Getting Started with SAP HANA: Beginner’s Guide 2025
Introduction
In today’s evolving digital landscape, the sheer volume of data is staggering. Businesses face an avalanche of information, and the key to success lies in their ability to efficiently analyze this data in real-time. Such analysis empowers them to make swift, well-informed decisions, boost operational efficiency, and cut IT costs. Enter SAP HANA, the cutting-edge solution that has become the go-to platform for organizations looking to streamline operations and gain a competitive edge.
The adoption of SAP HANA as a platform makes it possible to realize the vision of a common data foundation, against which both analytical and transactional processes are executed.
We understand that delving into SAP HANA can be overwhelming due to the wealth of information available. Fear not!. Through this technical blog, we are here to guide you on a structured journey through the world of SAP HANA. Our goal is to provide you with a comprehensive understanding, from its architecture and features to the benefits and practical use cases.
So, let’s dive in and unlock the power of SAP HANA together. Whether you’re an IT enthusiast or a business professional, we’ll ensure you gain a clear understanding of how SAP HANA can add value to your endeavors.
Evolution
The Birth of SAP
In April 1972, SAP emerged on the scene, marking a significant milestone in the world of enterprise software. Instead of crafting custom programs for individual clients, SAP pioneered the development of standardized solutions, ushering in a new era for businesses.
- As the importance of business data grew, SAP recognized the need to consolidate it into a single repository to ensure the security of transactions. This realization gave birth to online transaction processing (OLTP) databases , designed to house all vital business data within a unified database.
- While OLTP databases excelled at transaction processing, they fell short in the area of business intelligence. Generating reports required predefinition and adhoc analysis was a distant dream. To bridge this gap, online analytical processing databases (OLAP) emerged, empowering high-speed reporting and structured data analysis.
- However, a bottle-neck remained. Data had to be extracted from the OLTP database, aggregated, and then loaded into the OLAP database. This cumbersome process led to slow staging cycles and reports that were perpetually outdated.
- Efforts were made to address these challenges through caching and business warehouse accelerators. Yet, issues of currency and granularity persisted. The architecture grew increasingly complex and costly.
A Game-Changing Innovation
In 2010, SAP in partnership with Berlin university and Hasso-Plattner Institute and Intel, developed an in-memory database known as SAP HANA. This groundbreaking innovation envisioned a common data foundation that could support both transactional and analytical processes.
- SAP HANA revolutionized the landscape by eliminating the need for staging and number-crunching processes. Analysis became lightning-fast, with data residing in-memory rather than on secondary devices (disks, tapes etc). This shift unleashed unprecedented real-time insights and new avenues for reporting and analysis.
- Deploying SAP HANA came with its challenges, requiring dedicated hardware and software investments that increased upfront costs and total cost of ownership (TCO).
- To address these concerns, SAP introduced the SAP HANA enterprise cloud, a virtualized infrastructure that enhances scalability and integration into existing data centers, ultimately reducing TCO.
- Today, SAP HANA serves as the cornerstone for all SAP solutions. Both existing and new solutions are designed with SAP HANA in mind from the outset. These solutions offer new interfaces and seamless mobile connectivity, simplifying operations and providing anytime, anywhere access to SAP systems
In summary, SAP’s solutions have undergone a remarkable evolution over the years. They now offer superior business insights and real-time data analysis, opening doors to novel business opportunities and models. With the SAP HANA Enterprise Cloud, businesses can streamline their operations and enhance accessibility to SAP systems, embracing a future driven by data and innovation.
Overview of SAP HANA
What is SAP HANA?
SAP HANA is an in-memory, columnar relational database management system. It combines both online transaction processing (OLTP) and online analytical processing (OLAP), in one database system. As a database server, its key function is to store and retrieve data as requested by the applications.
An in-memory database (IMDB) like SAP HANA take a radically different approach to data storage. Unlike traditional databases that rely on external devices such as disks or solid-state drives (SSD), SAP HANA stores data right in the server’s main memory (RAM). This shift to in-memory storage opens up a world of possibilities.
SAP HANA caters to applications that demand lightning-fast responses and instantaneous data retrieval. By keeping the data in main memory, it eliminates the lag associated with disk-based systems. Imagine fetching data in the blink of an eye; that’s the magic of SAP HANA.
Some of the versatile features that in-memory technology brings to the table are:
- Efficient RAM Utilization: Stores major chunk of information compressed in main memory (RAM).
- Parallel Processing: System leverages multiple processor cores for parallel processing, enhancing performance.
- Data Intensive Computation: For faster processing, it transfers data-intensive computations from application layer to database layer, optimizing workloads on your applications.
Features of SAP HANA
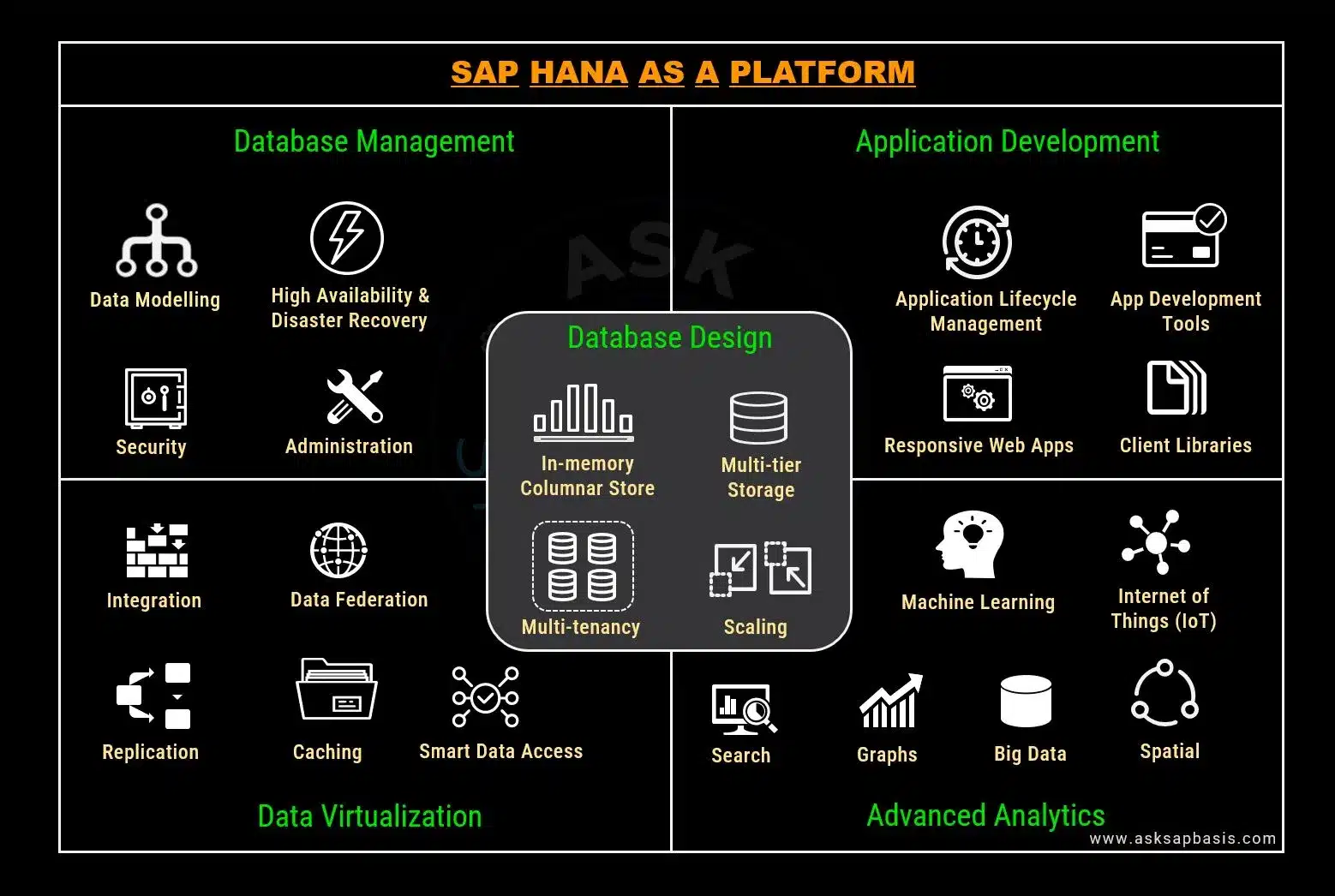
- In-Memory, Columnar Database
- SAP HANA is an in-memory, columnar, massively parallel processing database that can handle both transactional and analytical workloads on a single platform.
- The system utilizes high-speed memory to store and organize data in columns (compressed), partitioning and distributing it among multiple servers to enable faster and more efficient queries than aggregate data, while avoiding costly full-table scans.
- ACID Compliance
- ACID is an abbreviation for Atomicity, Consistency, Isolation & Durability
- Compliance to ACID standard ensures to maintain data integrity and consistency for analytical and transaction purposes.
- Multi-Tenancy
- Multi-tenancy architectures allows multiple tenant (or clients) to operate in a single system, sharing the same memory and processors.
- Each tenant database is fully isolated, with its own database users, catalog, repository, data files and log files for maximum security and control.
- Multi-Tier Storage
- Multi-tier storage uses different types of storage media & technologies to manage data based on its usage pattern and access frequency.
- SAP HANA enables software solutions to manage multi-temperature data in terms of hot, warm and cold storage, optimizing the cost and performance of storage.
- The system’s native storage allows for intelligent data management between memory and persistent storage such as SAP HANA cloud data lake.
- Scaling
- SAP HANA supports vertical and horizontal scaling. Horizontal scalability involves adding more servers to a cluster to increase processing power. Vertical scalability involves adding more memory or processors to a server to increase its capability.
- SAP HANA accommodates terabytes of data in a single server. It further expands by implementing a shared-nothing architecture across multiple servers in a cluster.
- Data Modelling
- Data modelling is a process of creating a conceptual representation of data structures and relationships within a system.
- SAP HANA’s in-memory technology enables application developer’s and modelers to create virtual data models that can be executed in real-time.
- This feature facilitates collaboration between stakeholders using graphical modelling tools that make data transformation and complex logic more accessible.
- Stored Procedures
- Stored procedures are pre-written, re-usable code blocks that are stored within a database and are called & executed by variety of applications.
- This stored procedures in SAP HANA provides advance capabilities to create more efficient procedures that can perform tasks such as data aggregation, transformation as well as transaction control.
- Furthermore, stored procedures are executed entirely in-memory, which increases their speed and efficiency to perform database operations.
- Security
- SAP HANA’s unique security features include real-time data anonymization and robust authentication, and authorization protocols.
- The security feature allows businesses to stay compliant with regulatory requirements, ensuring that they meet data protection and privacy standards.
- Administration
- SAP HANA offers comprehensive administration tools for various platform lifecycle, performance, and management operations.
- These tools enables users to manage platform resources efficiently, including starting, stopping, and restarting the system, as well as system backup and restore.
- Additionally, the administration tools allow for easy system automation and scaling.
- High Availability and Disaster Recovery (HADR)
- SAP HANA supports high availability and disaster recovery (HADR) to meet broad range of service levels.
- It leverages various techniques such as backup, synchronous, asynchronous and multi-target system replication, storage mirroring, auto restart, auto failover and hot standby.
- This allows businesses to ensure that their data is always available, reducing the likelihood of downtime and loss of revenue.
- Data Integration
- Combining data from various sources into a unified format is data integration. It allows users to make informed decisions.
- SAP HANA’s ETL/ELT, data transformation, and data quality services aid in the process.
- Data Replication
- Copying data from one system to another is data replication.
- Real-time replication, bulk-load replication and data enrichment services are provided by SAP HANA to ensure target system’s data is always up-to-date and accurate, to make informed decisions.
- Data Federation
- Federation in SAP HANA is the ability to access data from remote systems and databases without copying it into SAP HANA.
- It provides real-time, lightning-fast access to remote data sources, including cloud-native sources such as Hadoop, Oracle, DB2, and others.
- Smart Data Access (SDA)
- Smart Data Access (SDA) in SAP HANA also allows users to access data from remote systems and databases without copying it into SAP HANA.
- SDA is supposed to be smarter and customized for particular conditions. For instance, SDA can automatically push down specific queries to the distant system for improved efficiency, as well as support new data sources such as Teradata, Microsoft SQL Server, and others.
- SDA is best-suited for large, complex, and distributed data, whereas data federation is ideal for relatively simple data that requires a unified view.
- Caching
- The concept of caching refers to the ingenious capacity to stash data in order to enhance federated inquiries targeted at far-off data sources.
- It permits one to exercise control over the sources and structures to which it is applied, as well as the timing and methodology by which the cache is refreshed.
- Application Lifecycle Management (ALM)
- ALM manages the entire lifecycle of an application, from building and packaging to deploying and upgrading. It ensures efficient development and delivery of high-quality applications.
- Application Development Tools
- Provides development tools for on-premises data modelling and application development constitutes a pivotal aspect of contemporary software engineering.
- Alternatively, the ABAP programming language, which is specifically designed for developing SAP application extensions, represents an alternative approach for this purpose.
- Client Connectivity
- SAP HANA’s enriched client libraries provides seamless connectivity to database from various application platforms and programming languages. These include, JavaScript, R, Java, Python and others.
- Responsive Web Applications
- SAP HANA offers a sophisticated HTML5 and JavaScript framework, leveraging the SAP Fiori UI, for creating dynamic and responsive web applications.
- With this framework, developers can design applications that are fully adaptable to different screen sizes, ensuring consistent and intuitive user experiences across various touchpoints.
- This flexibility enables seamless deployment and utilization of these applications across multiple devices, without any need for additional customizations or alterations.
- Search
- To efficiently search for text across multiple columns and textual content, SQL provides various methods such as full-text and advanced fuzzy searches.
- Full-text search allows for searching a database using natural language queries, including keywords, phrases, and synonyms.
- Advanced fuzzy searches can be used to locate information that may not match the exact search criteria.
- With the right combination of search methods and database design, users can locate the desired information quickly and accurately.
- Machine Learning (ML)
- SAP HANA supports machine learning through the utilization of various libraries and tools, such as the SAP HANA Predictive Analytics Library (PAL) and the SAP HANA Automated Predictive Library (APL).
- These libraries allow users to build and deploy machine learning models within the SAP HANA environment, using a variety of algorithms and techniques.
- Spatial Processing
- SAP HANA natively supports spatial data types and functions, enabling spatial processing. You can use SQL through open standards to store, query, and access location-enabled content.
- Graphs
- A property graph is a form of a graph database in SAP HANA that represents data as a set of nodes and edges, with each one having properties or attributes associated with it such as names, dates, or numeric values.
- The graph can be beneficial in highly inter-connected data streams such as social networks, supply chain networks and financial transactions
- With a property graph in SAP HANA, you can simply store, process, and analyze this sort of data, as well as integrate it with other functionality for sophisticated analytical processing.
Benefits of SAP HANA
SAP HANA is a versatile database, and is more than just a reliable data storage and retrieval system. It offers several advantages that are often overlooked.
Rapid Data Processing
- One of the most significant feature of the SAP HANA database is its remarkable processing speed. It excels at handling and processing vast amounts of data in real-time, with its cutting edge in-memory computing technology.
- This means that organizations can make quick and informed decisions based on the up-to-date data, thereby enhancing overall efficiency and productivity.
Advanced Analytics & Insights
- SAP HANA extends its capabilities far beyond conventional databases by offering advanced analytics features, including predictive analytics and machine learning. This empowers organizations to tap into the potential of their data, extracting invaluable insights to guide intelligent decision-making.
- With SAP HANA’s built-in analytics capabilities, users can seamlessly and easily craft reports and dashboards, providing visual representations of data and unearthing crucial insights into their business operations.
- This insights can serve as a compass, guiding organizations towards areas of improvement, operational optimization, and increase profitability.
Robust Security
- SAP HANA doesn’t compromise when it comes to safeguarding your data. It comes equipped with a robust suite of security features, encompassing data encryption, user authentication, and access control.
- With these defenses in place, enterprises can confidently rest assured that their data remains impervious to unauthorized access and cyber threats.
Diverse Integration
- One of the standout advantage of SAP HANA database is its seamless integration with both SAP and third-party products.
- This integration empowers organizations to harness the full potential of SAP’s comprehensive suite of products and solutions, thereby enhancing their overall operations.
- For instance, SAP HANA can seamlessly integrate with SAP Business Warehouse (BW), providing real-time analytics and reporting capabilities, which can be a game-changer for businesses seeking actionable insights.
Cost Savings
- SAP HANA also plays a pivotal role in helping organizations reduce costs. Its in-memory technology minimizes the need for expensive hardware and infrastructure investments.
- Additionally, SAP HANA’s advanced analytics capabilities enable organizations to identify areas for cost savings and operational optimization, thus bolstering their financial efficiency.
Rapid Scalability
- SAP HANA offers unparalleled scalability, ensuring organizations can adapt to changing data volumes and processing needs across distributed environments. This scalability is twofold, encompassing horizontal and vertical options:
- Horizontal Scalability: This involves the addition of more servers to a cluster, effectively boosting processing power to meet growing demands.
- Vertical Scalability: In this approach, more memory or processors are added to a server, enhancing its capability to handle data and applications efficiently.
- This adaptability guarantees that organizations can effortlessly keep pace with increasing data volumes and processing requirements, regardless of their IT infrastructure setup.
Efficiency
- Efficiency lies at the heart of SAP HANA’s capabilities, revolutionizing data management with advanced techniques such as data silo reduction, advanced compression, footprint elimination, and data duplication eradication.
- Advanced Compression: SAP HANA ensures data is stored efficiently, occupying less storage space without compromising data quality or accuracy. This not only results in cost savings but also accelerates data retrieval, contributing to operational efficiency.
- Data Silo Reduction: Data silos, which hinder information access and management due to data being stored in different formats or locations, are efficiently reduced by SAP HANA.
- Footprint Elimination: SAP HANA’s streamlined computing architecture eliminates the need for sums, indexes, materialized views, or aggregates, effectively reducing database footprints and enhancing operational efficiency.
In conclusion, SAP HANA transcends the conventional perception of a database. It stands as a strategic asset that offers seamless integration, cost-saving opportunities, rapid scalability, and unmatched data management efficiency for organizations. Embracing these benefits empowers businesses to make informed decisions, optimize operations, reduce costs, and maintain a competitive edge in today’s data-driven landscape.
SAP HANA Vs Traditional RDBMS
| SAP HANA | Traditional RDBMS |
| In-memory database | Disk-based database |
| Entire data is loaded into memory | Entire data is stored onto disk. |
| Supports massive parallel processing | Generally only one core is responsible for one query execution. |
| Real-time data processing and analytics | Does not support real-time processing and analytics |
| Allows both column-based storage model optimized for analytics and row-based storage for transactional processing | Allows only row-based storage model optimized for transactional processing |
| Advanced data compression techniques | Traditional compression techniques |
| Native support for unstructured and semi-structured data | Requires additional tools to handle such data types |
| Built-in support for advanced analytics such as predictive analytics and machine learning | Requires additional tools and integration to support advanced analytics |
| Supports multi-tenancy | Does not offer multi-tenancy |
| High level of data security and privacy features | May require additional tools and configurations to achieve similar security |
Advantages Over Traditional RDBMS
| Challenges with Traditional RDMS | How SAP HANA Steps-In |
| Slow Data Processing | 1) SAP HANA is an in-memory database, which stores data in the main memory for faster access and processing. 2) It also offers advanced query optimization and parallel processing techniques, resulting in significantly faster data processing. |
| Limited Analytics Capability | 1) SAP HANA provides native support for advanced analytics, such as predictive analytics and machine learning, allowing for more in-depth analysis of data. 2) It also offers services such as SAP HANA Analytics and SAP HANA Predictive Analytics Library to help users analyze data more effectively. |
| Inefficient Data Compression | 1) SAP HANA offers advanced data compression techniques, such as column-based storage and delta encoding, which significantly reduce the storage requirements and memory usage. 2) It also offers services such as SAP HANA Dynamic Tiering to optimize storage usage. |
| Inability to Handle Unstructured and Semi-Structured Data | 1) SAP HANA provides native support for handling unstructured and semi-structured data types, such as JSON and XML, enabling users to work with different data types more efficiently. 2) It also offers services such as SAP HANA Smart Data Integration to easily integrate data from multiple sources. |
| Lack of Real-Time Processing | 1) SAP HANA offers real-time data processing and analytics, allowing for more accurate and timely decision-making. 2) It also offers services such as SAP HANA Streaming Analytics to analyze and process data in real-time. |
| Limited Data Security and Privacy Features | 1) SAP HANA provides a high level of data security and privacy features, such as data encryption, access controls, and auditing, to ensure that data is secure and private. 2) It also offers services such as SAP HANA Dynamic Authorization Management to manage and control user access to data. |
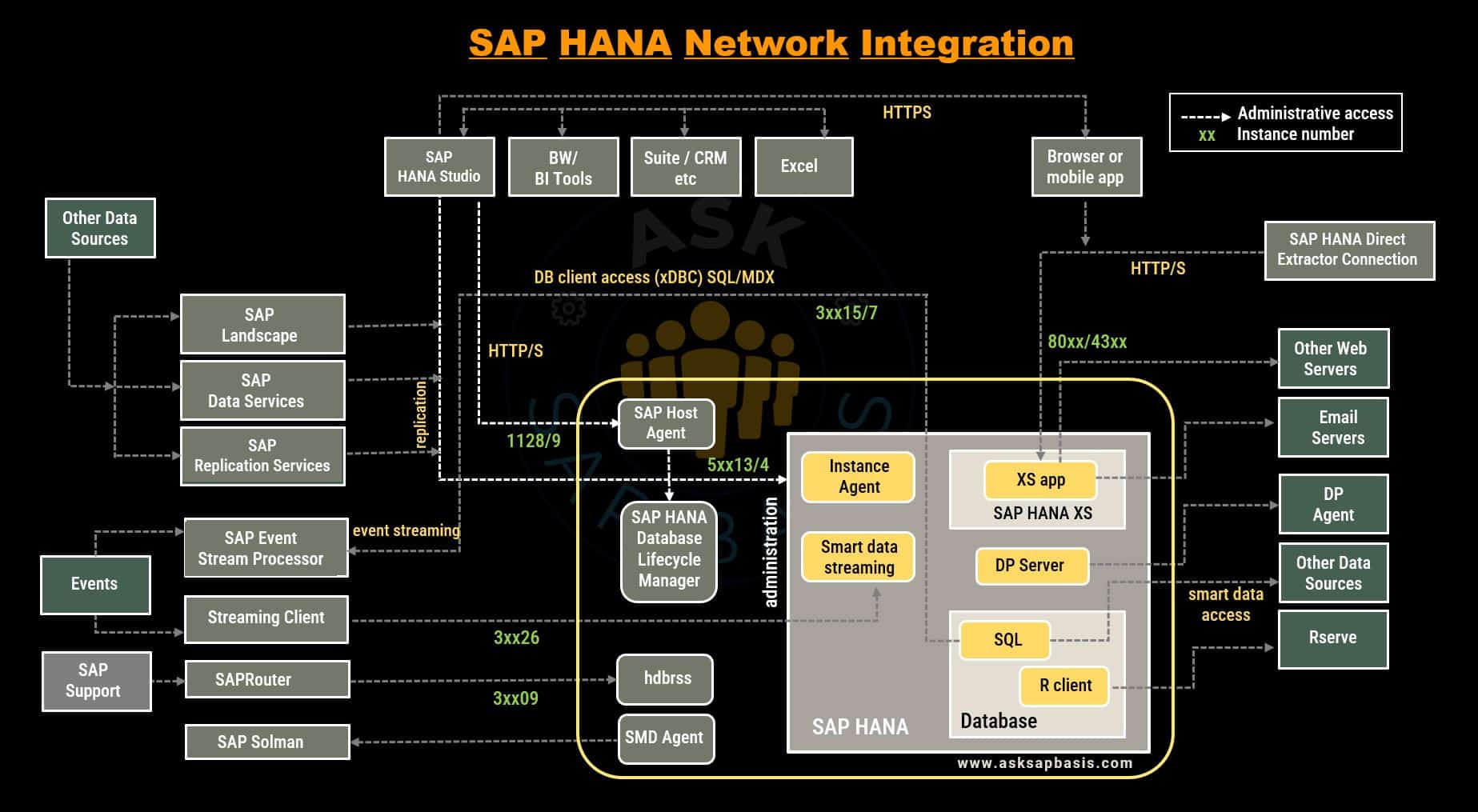
SAP HANA Architecture
Components Overview
SAP HANA system architecture comprises several main and auxiliary server components that work together to provide the full functionality of the SAP HANA platform.
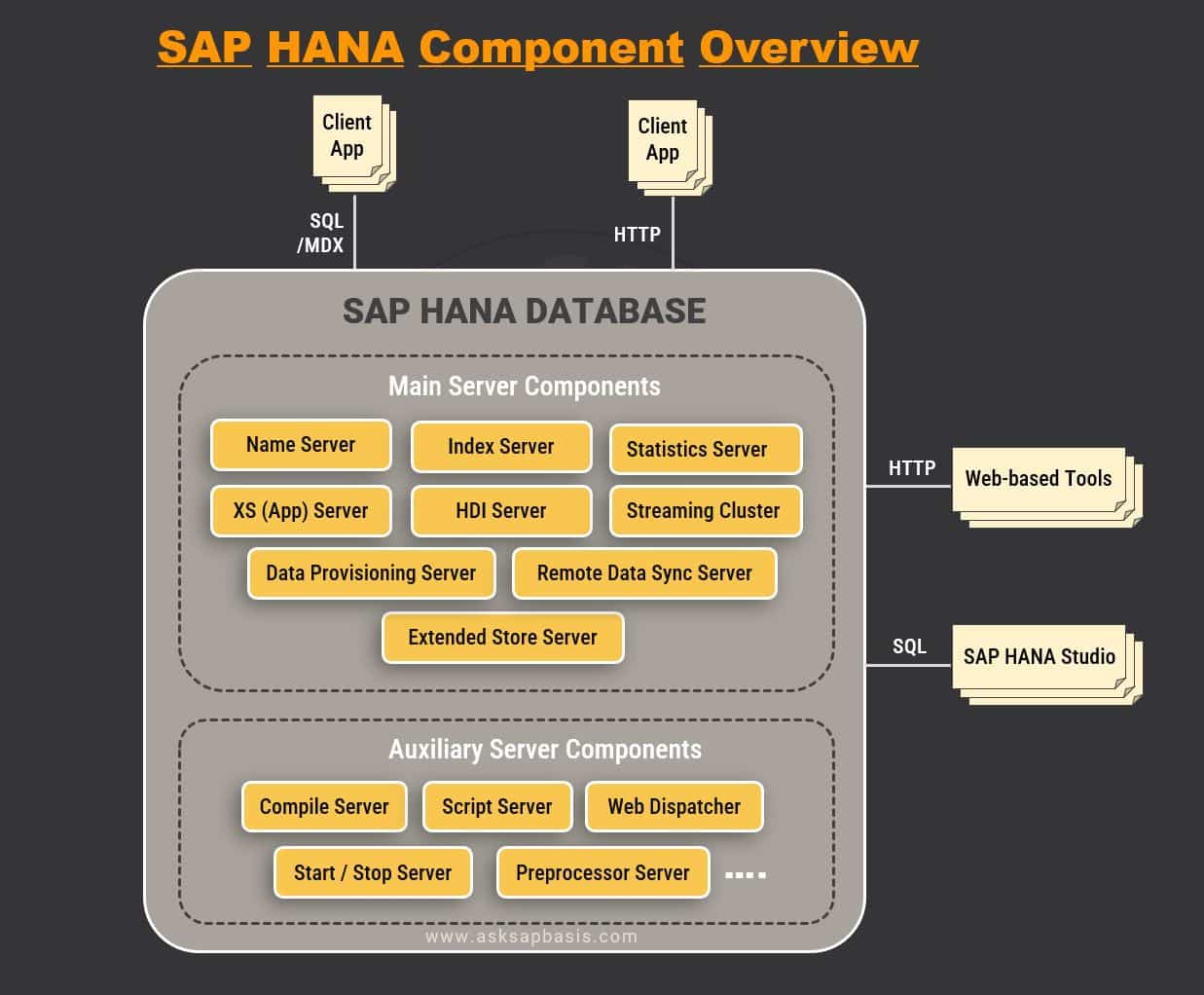
| Component | Description |
| Index Server | It is one of the key components of SAP HANA, that manages the actual data and processes it using engines (SQL engine, calculation engine etc). |
| Name Server | It is the central component that manages the configuration and metadata of the SAPHANA system. In a distributed environment, it maintains a list of all the server components that are running and their status. |
| XS (App) Server | It is a lightweight application server that provides platform for developing and deploying native SAP-HANA web applications. It supports multiple programming languages and allows developers to build applications without the need to run an additional application server. |
| Statistic Server | It collects performance data and statistics from various components in SAP HANA system. The data is utilized by administrators and developers to optimize system performance. |
| Streaming Server | It provides smart real-time data processing and analysis. It is main component that manages and coordinates the flow of data in the streaming pipeline. |
| SAP HANA Deployment Infrastructure (HDI) Server | It provides standardized way to deploy and manage database artifacts such as tables, views and procedures. |
| Data Provisioning Server | It provides centralized platform for loading data from various sources into SAP HANA database. It contains features that facilitates data integration, data transformation and mapping, data quality and cleansing. It also supports range of data replication and extraction methods, including log-based replication, trigger-based replication and ETL-based replication. |
| Remote Data Sync Server | It allows session-based synchronization between remote systems and SAP HANA database in real time. It enables users to replicate and synchronize data from SAP, Non-SAP, mobile and IOT devices. |
| Extended Store Server (ESS) | It offers disk-based column store with high performance capabilities for very big data up to the petabyte range. |
| Compile Server | It optimizes the server response times by compiling stored procedures and programs. It runs on every host and stores execution plans in memory for subsequent use. |
| Script Server | It executes libraries of application, written in C++. It has to be manually started. For more details, refer to SAP Note 1650957. |
| Preprocessor Server | It analyzes text data and extracts information that is used by the index server to provide text search capabilities in SAP HANA. |
| Start/Stop Server | It is responsible for starting and stopping services in sequential order. It also monitors their runtime state. |
| Web Dispatcher | It acts as a reverse proxy for inbound HTTP and HTTPS connections to application server. |
Index Server Architecture
The cornerstone of SAP HANA’s data management prowess lies in its Index Server, a pivotal component responsible for managing data stores and processing engines. When authenticated sessions and transactions sends SQL or MDX statements, the index server is responsible for handling them.
Let’s dive into detailed understanding of each architectural component of index server.
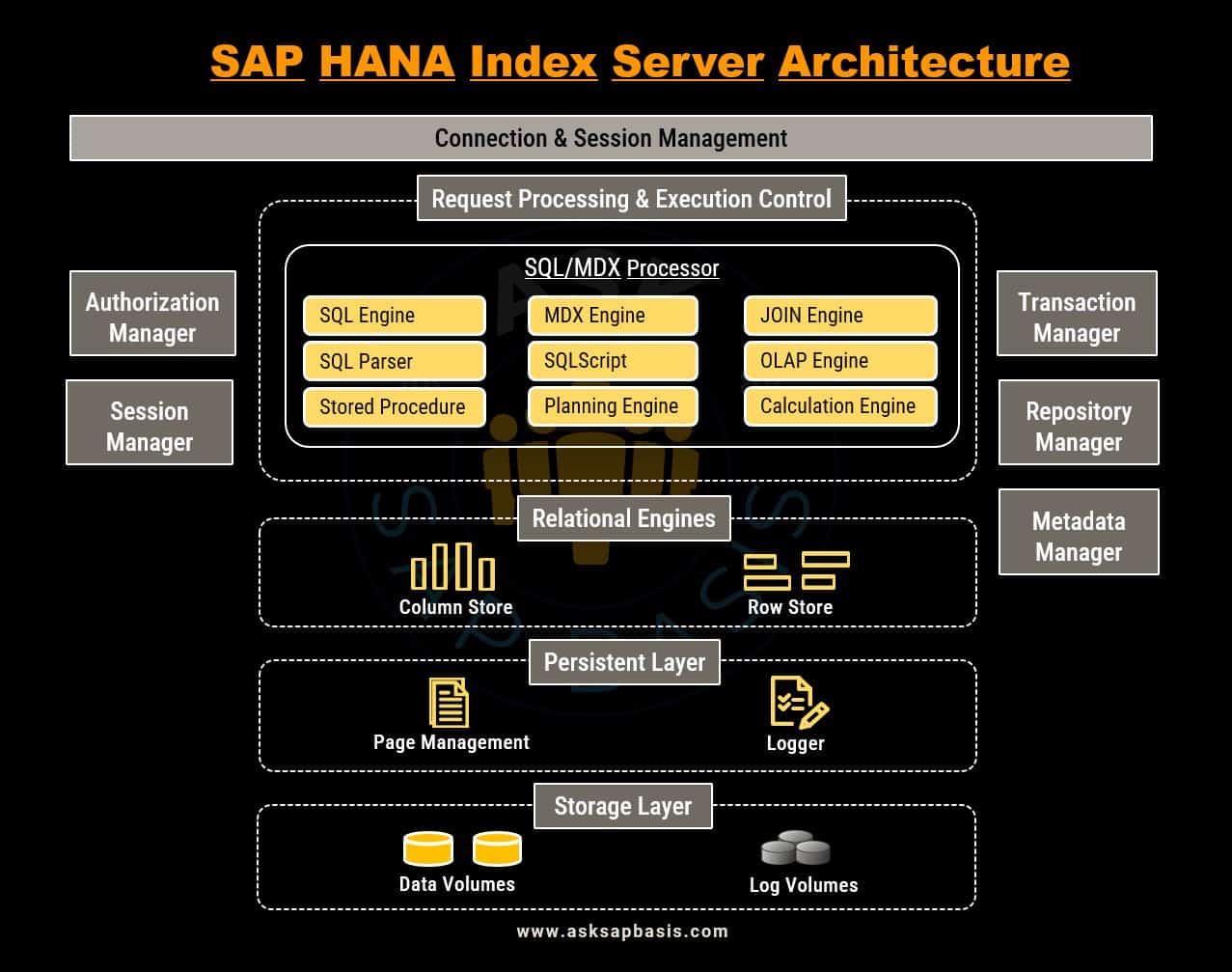
Connection and Session Management
- The SAP HANA database initializes and manages connections and sessions using pre-established session parameters to accommodate complex securities and data transfer policies.
- Connections can be established through various protocols such as JDBC, ODBC, SQL and HTML.
- Connection management plays a critical role in monitoring and controlling concurrent connections to prevent overloading the system.
- A session represents an interactive session between a user and the database. It includes information such as user authentication credentials and database queries.
- Session management tracks and manages user sessions, optimizing query execution and caching.
SQL / MDX Processor
- The SQL processor within SAP HANA optimizes data query performance by segmenting and directing queries to specialized query processing engines.
- It also ensures the authorization of SQL statements, enhances efficiency through error handling, and assists in generating optimized query plans.
SAP HANA has different engines to process different views. Some of the them are:
- Planning Engine: Facilitates planning, budgeting, and forecasting by analyzing past data and performance indicators to project future scenarios.
- Join Engine: Optimizes the processing of joins and attribute views with techniques like parallelization and column store optimization.
- OLAP Engine: Used to process analytical view. Analyzes large datasets to produce summary reports for business intelligence and decision making process.
- Calculation Engine: Handles complex calculation, including statistical analysis, predictive modelling, and machine learning.
- SQLScript: Used for developing custom business logic, data transformation and data validation routines.
- SQL Parser: Responsible for analyzing and interpreting SQL statements. When a client application sends a SQL query to the server, SQL parser analyzes the syntax of the query, checks for errors, and generates internal representation of query. It enables efficient and accurate processing of SQL queries.
- SQL Engine: Receives SQL queries from client applications and translates them into executable instructions for the database.
- Multi-dimensional Expression (MDX) Engine: MDX is a query language used to extract data from multi-dimensional databases such as online analytical processing (OLAP). MDX engine is used to create complex queries and retrieve data from multiple dimensions, measures, and hierarchies.
Relational Engines
- The relational engines in SAP HANA Index server utilizes both column-store and row-store.
- Column-stores excel in analytical workloads requiring rapid processing of large data volumes. Row-store are suitable for transactional workloads, characterized by frequent data access and updates by row.
Persistent Layer
- It is tasked with maintaining transaction durability and atomicity.
- It tracks committed states of transactions and writes them to disk. They ensures that transactions are executed entirely or not at all, allowing the database to be restored to the latest committed state after a system restart.
Transaction Manager
- In the HANA database, SQL statements are executed within the scope of a transaction.
- The transaction manager oversees the entire transaction process, managing isolation levels, and monitoring running and completed transactions.
- It ensure that transactions are atomic and durable, even in the event of a system failure, providing effective and reliable transaction management for users and applications.
Metadata Manager
- It serves as a central repository for all metadata related to data objects (tables, views, columns, indexes, procedures etc).
- It stores all metadata in a unified database catalog, offering a comprehensive view of data objects and processes in the database.
- It also supports transaction handling and multiple versions simultaneously, making it a vital tool for efficient data management in SAP HANA.
Authorization Manager
- It ensure users have the necessary privileges for requested operations. Allows administrators to grant permissions for specific operations or objects based on user’s need and responsibilities.
- This manager supports complex access control policies and integrates with external authentication systems like LDAP or Active Directory, bolstering security.
In conclusion, SAP HANA’s Index Server architecture is a robust framework that orchestrates data processing, session management, query optimization, data storage, transaction management, metadata handling, and access control. Understanding the intricacies of this architecture is essential for harnessing the full potential of SAP HANA’s data management capabilities.
How SAP HANA works?