
SAP HANA System Replication: 28 Essential FAQs & Answers
Purpose
This blog uncovers the fundamentals of SAP HANA System Replication (HSR), providing a clear understanding of both basic and advanced concepts essential for architecting high availability in SAP environments. Whether you’re just starting your SAP journey or looking to deepen your expertise, this guide offers valuable insights and practical tips tailored for learners at all levels. Additionally, these FAQs serve as a comprehensive resource for interview preparation, ensuring you’re well-equipped with the knowledge needed to excel.
SAP HANA System Replication FAQs
1) What is SAP HANA System Replication?
SAP HANA system replication is a high-availability and disaster recovery solution that ensures data and services remain available by replicating data from primary SAP HANA system to a secondary HANA system, situated within the same or another data center.
2) What is the purpose of SAP HANA System Replication?
The primary purpose is to ensure business continuity, by providing a standby database that can swiftly takeover in case the primary system becomes unavailable due to hardware failure, maintenance or disasters. It maintains data availability and consistency across primary and secondary systems, ensuring continuity of operations in case of system failures or disasters.
3) What is the use cases of SAP HANA System Replication?
SAP HANA system replication typically designed for high availability and disaster recovery.
SAP highly recommends using HANA system replication to manage downtime caused by scheduled maintenance, faults and unforeseen catastrophes. This approach ensures a recovery point objective (RPO) of zero seconds and a recovery time objective (RTO) that’s measured in minutes.
4) What is the meaning of SAP HANA High Availability mean?
SAP HANA high availability ensures uninterrupted access to the database by leveraging strategies that minimizes downtime during failures. It employs redundant systems to automatically take over, if one fails, maintaining continuous availability and preventing data loss.
SAP HANA system replication provides high availability solution that supports both fault tolerance and disaster tolerance.
- Fault tolerance enables the swift transition to the operational state of the SAP HANA database within a single data center.
- Disaster tolerance refers to extended failover capabilities across datacenters. It facilitates rapid recovery of the SAP HANA database in the event of significant disruption or catastrophe, ensuring operational continuity.
5) Can I use SAP HANA system replication for migration purposes?
Yes, SAP HANA system replication can be used for migration purposes, although its primary designed for high availability and disaster recovery.
When migrating from one SAP HANA environment to another, you can setup replication between source and target system. This allows to minimize downtime and data loss throughout the migration process. However, remember that SAP offers dedicated migration tools and methods, like the Database Migration Option (DMO), optimized for migration scenarios and capable of delivering a smoother experience.
It is advisable to thoroughly assess your migration requirements and consider using the appropriate tools and procedures based on your specific situation.
6) What are the network recommendations for SAP HANA system replication?
- The network latency is determined by the selected replication mode.
- If the distances between two datacenters is less than100 kms, we recommend synchronous replication modes (SYNC or SYNCMEM).
- If the distances between two datacenters exceeds 100 kms, it is recommended to use asynchronous replication mode (ASYNC).
- The selected operation mode influences the requirements for network throughput.
- The selected operation mode affects the size of data transported across the network.
- To estimate the necessary throughput, you must understand the sizes of the data and logs generated during your daily workload.
- You can acquire this information by utilizing one of the SQL statements within the attached zip file of SAP Note 1969700.
- You can configure data and log compression to decrease traffic between systems, especially over long distances (such as, when using the ASYNC replication mode).
7) What is the difference between synchronous and asynchronous replication?
- Synchronous replication ensures data consistency between the primary and secondary sites in real-time. However, it might introduce higher latency because it need to wait for acknowledgement from the secondary location. It is designed typically to provide high availability to critical application, ensuring zero data loss.
- Asynchronous replication introduces some delay but can offer better performance. Its design enables it to function over long distances, making it optimal choice for less critical applications that can allow some degree of data loss. Also, it is more cost effective and requires less bandwidth as compared to synchronous replication.
Synchronous replication is best choice for scenarios that demand immediate disaster recovery and projects mandating absolute zero data loss. In contrast, asynchronous replication is the preferred choice for projects that require immediate disaster recovery, can tolerate partial data loss and involves storing less sensitive data.
8) Which SAP HANA system replication modes are available ?
| Replication Mode | Description | Response when secondary system is not available |
| Synchronous (SYNC) | Primary system waits until the secondary system receives and persists the data to disk. | Primary system waits either for an error to be returned or until timeout (default: 30 sec) occurs. |
| Synchronous (SYNC MEM) | Primary system waits until the secondary system acknowledges the data. | Primary system waits either for an error to be returned or until timeout (default: 30 sec) occurs. |
| Synchronous (FULL) | Primary system awaits the secondary system to receive and persist the data to disk. | Primary system remains blocked until the secondary system becomes available. |
| Asynchronous (ASYNC) | Primary system does not wait for the acknowledgement from the secondary system. | Primary system proceeds without replicating data. |
9) Which SAP HANA system operation modes are available?
| Operation Modes | Description |
| Logreplay | This default operation mode operates with continuous redo log shipping after the initial full data configuration. Continuous log replication enables immediate takeover by the secondary system upon primary system failure. |
| Delta_datashipping | This mode combines delta data shipping (usually every 10 secs) with continuous log shipping for replication. Secondary system stores log entries, replaying at takeover. The takeover involves redo log replay upto the latest delta data shipment. |
| Logreplay_readaccess | This mode is required for replicating to an active/active (read-enabled) secondary system. Enables direct connection for read access during replication setup. Eliminates the necessity for delta data shipping, thus reducing takeover time. |
For more details on replication and operation modes, kindly refer to the blog, SAP HANA: High Availability (HA) Solutions.
10) Can I use mixed or different operation modes in multi-tier system replication?
- Since SAP HANA 2.0 SP00, system replication can be run in three different operation modes.
- In multi-tier system replication, you generally use only one operation mode for whole landscape.
- However, there is one exception: If you use “logreplay_readaccess” mode between primary (tier-1) and secondary (tier-2), then operation mode “logreplay” is allowed between secondary (tier-2) and tertiary (tier-3).
- By using the operation mode “logreplay”, you transform your tertiary site in SAP HANA replication into a HotStandby system.
- With SAP HANA 2 SPS04, logreplay_readaccess actively supports multiple secondary systems in multi-target system replication
11) Is it possible to utilize SAP HANA system replication for system copies?
SAP HANA system replication is primarily designed for high availability and disaster recovery purposes. However, it serves as dual role by facilitating an effective solution for system copies as well.
After the initial synchronization, the replication side can function as a copy system through a takeover process. This approach significantly expedites system copying compared to conventional methods like backup and restore.
If renaming the SAP HANA database is necessary for the system copy, the hdbrename tool can be utilized. Prior to productive use of the copied system, ensure installation of a valid license. Just ensure to install a valid license before placing the system to productive use.
Please note, the number of worker hosts on the copied system, needs to be identical to the original number of working hosts (standby hosts can differ).
12) What are the pre-requisites for setting up SAP HANA system replication?
The pre-requisites for SAP HANA system replication include:
- Use different hostnames for both primary and secondary system.
- Number of worker nodes in both primary and secondary system must be same.
- SAP does not support system replication between two systems on the same host.
- Perform an initial full data backup or snapshot on the primary system before setting up system replication.
- SAP HANA software version of secondary system has to be equal or newer than the one in primary system.
- After installing and configuring both the primary and secondary systems, independently verify their operational status.
- Secondary system should have same SID, instance number, as that of primary. this replicates all the license information to secondary system.
- Manually duplicate changes made to the .ini configuration file to the other system, in order to ensure consistency.
- Execute all configuration steps on the master name server node, which for SAP HANA Tenant Database Systems is the System DB (not on the tenant DBs).
- Ensure that the required ports are available, with both the primary and secondary systems using the same. Also, ensure that <instance number>+1 is available on both systems, as this port range facilitates communication for system replication.
- In HANA 2.0, copy the system PKI SSFS key ((Public Key Infrastructure / Secure Store in File System) and data files from primary and secondary systems following SAP Note 2369981. The files are located here:
- /usr/sap/<SID>/SYS/global/security/rsecssfs/data/SSFS_<SID>.DAT
- /usr/sap/<SID>/SYS/global/security/rsecssfs/key/SSFS_<SID>.KEY
- Configuring system replication between SAP HANA single container systems (default until HANA 2.0 SPS00) and SAP HANA Tenant Database System (default as of HANA 2.0 SPS01) is not supported.
13) Can backups be taken on the secondary site?
Currently, you have the capability to exclusively conduct backups on the primary site.
After takeover of the secondary site and with the automatic log backup feature enabled, the system will automatically store log backups at that secondary site.
14) Can systems with different operating systems perform system replication?
Yes, systems with different operating systems or operating system versions support system replication, provided they are compatible with your version of HANA.
However, please note that setting up system replication between platforms with different endianness is not possible, due to binary incompatibility of the logs. SAP HANA systems are generally little-endian, with the exception of IBM Power systems in combinations with SLES 11.x
Refer to SAP Note “2235581 – SAP HANA: Supported Operating Systems“
15) Can I use different hardware for primary and secondary sites?
Yes it’s possible. However, it is advisable to maintain similar hardware configuration to ensure compatibility and minimize performance discrepancies during failures.
16) How does SAP HANA system replication handle licensing? Is an additional license needed for secondary system?
In SAP HANA system replication, this is how licensing works:
- In SAP HANA system replication, both the primary and secondary HANA databases share the same SID, eliminating the need for an additional license.
- When you register a secondary HANA database, the primary HANA database automatically transfers the relevant permanent license key details to the secondary database and an automatically generated hardware key as primary key, ensuring license key validity.
- If you deregister the secondary database from system replication, it reverts to its original hardware key generated during installation.
- After restarting the secondary database in its new independent state, it detects the hardware key change. Since it had a valid permanent license before, an automatic installation of a 90-day temporary license key occurs.
- This temporary license key grants a 90-day grace period for the database administrator to obtain and apply a new valid license key for the independent database.
You can find more information about licensing in SAP HANA system replication in SAP Note 2211663.
17) What are the different methods to setup HANA system replication?
You can configure HANA system replication via three methods:
- Using the console (via command line)
- SAP HANA Cockpit
- SAP HANA Studio
18) Is it possible to set up a cascaded multi-tier system replication?
- Starting with HANA 1.0 SPS07 with multi-tier system replication, you can use synchronous system replication as the source for asynchronous replication in a cascading setup of primary site (tier-1), secondary site(2-tier) and tertiary site (3-tier).
- Prior to HANA 1.0 SPS11, the primary system (tier-1) was required to replicate synchronously to the secondary site (tier-2), and the secondary site (tier-3) had to replicate to the secondary site (tier-2) asynchronously.
- Starting with HANA 1.0 SPS11, a multi-tier landscape offers a broad range of viable replication mode combinations, encompassing SYNC, SYNCMEM and ASYNC. You can consult SAP Note 2303243, for the supported combination.
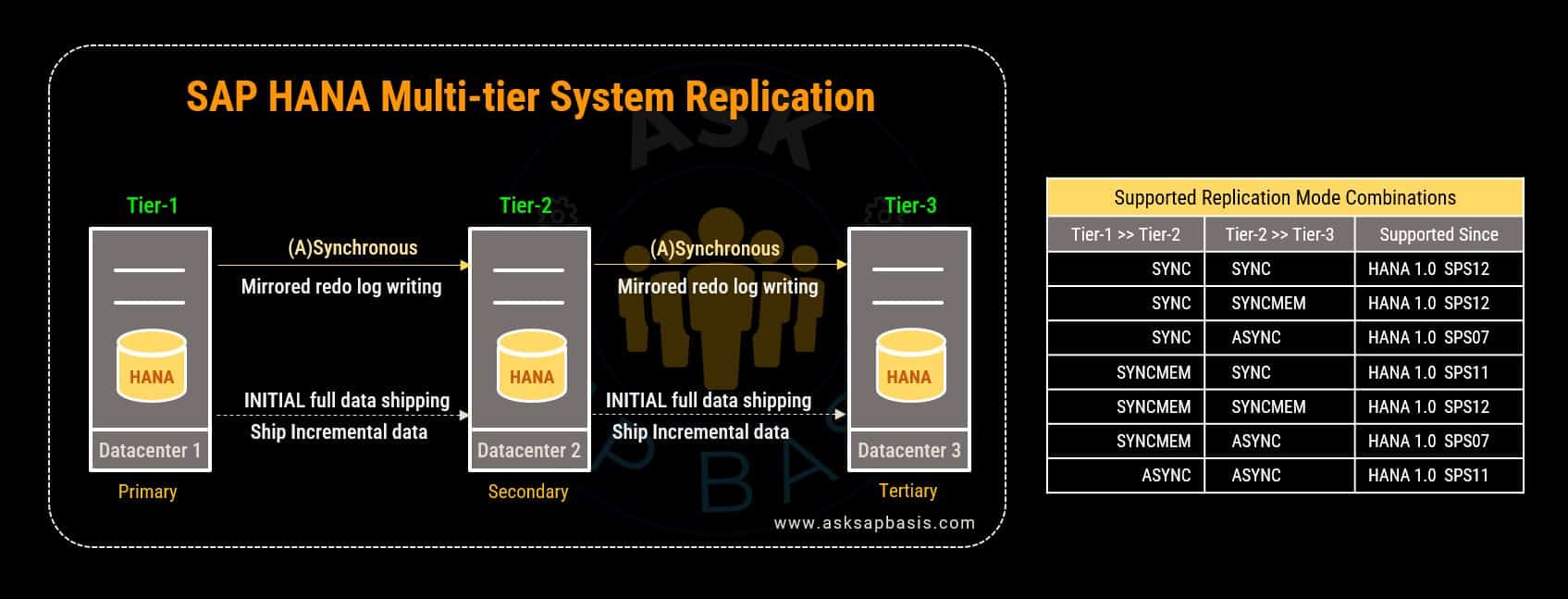
- For all multi-tier and multi-target replications, it necessary that the operation modes remains identical. Combining different modes, such as having “delta_shipping” from tier-1 to tier-2 and “logreplay” from tier-2 to tier-3 is not permissible. The only exception to this rule is the combination of “logreplay_readaccess” from tier-1 to tier-2 and “logreplay” from tier-2 to tier-3.
- To provide flexibility in adapting intricate system replication scenarios, you have the option to define the following parameter:
global.ini -> [system_replication] -> propagate_log_retention = true
This parameter guarantees the retention of redo logs across all sites, determined by the minimum savepoint log position across all systems.
19) After setup, can you change the replication mode between the primary and secondary systems?
- You can change the replication mode without the need for a full data transfer from primary to the secondary system afterward. You can execute the below command on the online or offline secondary:
hdbnsutil -sr_changemode –mode=sync | syncmem | async
- You can check whether the mode change was executed correctly with the follow command in M_SERVICE_REPLICATION view:
hdbnsutil -sr_state –sapcontrol=1
20) Is it possible to replicate multiple SAP HANA database to the same target?
You cannot replicate multiple SAP HANA databases into a single target SAP HANA database.
However, replicating different source SAP HANA databases into separate target SAP HANA databases on the same target host is supported. Ensure that you take into account the limitations outlined in “SAP Note 1681092 – Multiple SAP HANA systems (SIDs) on the same underlying server(s)“.
21) Is is possible to replicate a primary site to more than one secondary sites?
Until SAP HANA 2.0 SPS02, the primary site could only replicate to a single secondary system. Starting with SAP HANA 2.0 SPS03, multi-target replication becomes available, enabling the connection of multiple secondary sites to the primary system.
22) Typically, how much time does it take to initiate the synchronization between the primary and secondary system from the start?
The time taken for initial synchronization between the primary and secondary systems from scratch can vary based on factors such as system complexity, data volume and network bandwidth. You can use the following formula as a rough thumb rule.
“initial synchronization time” >= “backup size” / “available network bandwidth”
If you use data compression, make sure to take into account the compression factor, which compares the size of compressed data to the size of uncompressed data.
“initial synchronization time” >= “backup size” * “compression factor” / “available network bandwidth”
23) How can you execute a takeover and a failover?
Change the role of your main system from the current primary to secondary.
Assign the former primary system as the new secondary within the current primary system. This action reverses the roles from their original setup.
24) Which types of takeovers are available?
There are different types of takeover’s that are available. Below are the ones:
- Standard Takeover: In this method, you execute a standard takeover when your primary system becomes unresponsive or unexpectedly stops working due to a critical issue, requiring downtime for repairs.
- Takeover with Handshake: You can perform a secure and seamless planned takeover while the primary system remains operational. During this process, it temporarily suspends all new write transactions on the primary system. The takeover is initiates only when the secondary system has access to all redo logs. This ensures data continuity and minimizes the risk of data loss during planned takeovers. However, please note the following limitations:
- Only compatible with secondary tier.
- Not suitable for dynamic tiering services.
- Invisible Takeover and Restart: In this method, you recover and restore the sessions state on the new primary system. Unlike standard takeover, this seamless process automatically reconnect clients and restore sessions, even after system crash. Dedicated client applications won’t experience this invisible takeover.
- Failback: Failback is the process of returning to the original or primary system after restoration or repair. It is essentially the reverse of a takeover. It occurs when the former primary system becomes operational again, allowing the workload to shift back from the secondary system. Also, during takeover, you can swap primary and secondary roles. In a failback scenario, you must register the former primary as secondary system with the currently active primary system.
25) Under what circumstances does a takeover makes sense?
A takeover makes sense if:
- If the primary site becomes unresponsive.
- The secondary node remains unaffected by the same issue.
- To resolve the outage, schedule downtime is necessary. This downtime includes actions like restarting the database or rebooting the physical server.
- If the secondary site’s takeover reduces the downtime and becomes available for system operations faster than restoring normal activity to primary node. However, this depends on the type of issue encountered.
On the other hand, there are some scenarios where a takeover should be avoided:
- If the primary site’s database experiences frequent crashes, there is a likelihood that the same issue could impact the secondary site.
- Slow query performance can be another concern. Depending on the root cause, it may also affect the secondary site.
- If you have identified data inconsistencies while transporting data to the secondary system via delta data shipping, it raises potential issues. Although delta data shipping usually excludes corrupt blocks identified by checksum verification, there are cases where physical block corruption can still propagate through this method.
26) What are the factors that influence the takeover time?
The take over time is influenced by various operation modes, each with distinct implications for expediting the process. In operation modes such as log_replay or log_replay_readaccess, the secondary site is promptly operational, leading to a swift takeover process.
However exceptions occur when a significant backlog of log replay exists. In such cases, it can elongate takeover time as the log replay must be completed for system synchronization.
- The operation mode delta_shipping, may require additional steps, thus typically resulting in significantly longer takeover time.
- Open Data Persistence based on Last Savepoint. This foundation step ensures data integrity before takeover initiation.
- Loading Row Store. This crucial data structure is loaded to establish operational state.
- Replay Redo Log. To bring secondary system up to date with latest transactions, the system replays redo logs.
- Rebuilding Row Store Index. To optimize data retrieval efficiency, the system rebuilds Indexes.
27) Can you move or copy tenant system between systems with system replication?
Beginning with SAP HANA 1.0 SPS12, you can securely copy and move data with near-zero downtime using HANA system replication.
28) Does SAP HANA replication support conversion from SAP HANA 1.0 single container to HANA MDC?
No, SAP HANA system replication does not support the conversion from single container to MDC.
Resources
- SAP HANA System Replication Guide
- How-To Guide of SAP HANA System Replication
- SAP Note 1844468: Homogeneous system copy on SAP HANA




