
Mastering SAP HANA Replication Strategies: A Practical Guide
Introduction
In today’s rapidly evolving digital landscape, the security and reliability of data are crucial. Enterprises rely heavily on robust data management systems like SAP HANA to ensure seamless operations, make well-informed decisions, and gain a competitive edge in the market. SAP HANA, with its high-performance capabilities, plays a pivotal role in modern data management strategies.
In this context, SAP HANA stands out as a high-performing, in-memory database and platform renowned for its exceptional performance. It offers a range of robust replication scenarios that significantly enhance high availability and disaster recovery while optimizing data distribution for greater efficiency.
In this article, we will explore key SAP HANA replication scenarios, highlighting their significant advantages. Additionally, we will present real-world use cases that demonstrate the practical application of these scenarios, illustrating their transformative impact on modern data management strategies.
Overview of HANA Replication
SAP HANA replication is a sophisticated process designed to duplicate data to a secondary HANA system configured identically to the primary system. This continuous data replication keeps the secondary system’s memory updated, ensuring that it mirrors the primary system. The secondary system can be located in the same data center or in a different one, providing flexibility and resilience. This proactive approach significantly reduces Recovery Time Objectives (RTO), ensuring uninterrupted operational continuity.
By leveraging various replication methods, SAP HANA helps businesses effectively mitigate risks associated with hardware failures, network outages, and other unforeseen disruptions. SAP HANA replication plays a crucial role in maintaining data consistency, enabling rapid recovery, and supporting seamless operations across multiple systems. This robust strategy ensures businesses remain resilient, operational, and ready to meet the demands of the modern digital landscape.
Achieving High Availability
Businesses achieve high availability by striking the right balance between reducing data loss and quickly recovering systems. This balance results from the interplay of two crucial factors:
- Recovery Point Objective (RPO)
- Recovery Time Objective (RTO)
1) Recovery Point Objective (RPO)
RPO defines the maximum allowable data loss that an organization can tolerate in the event of a disruption or failure.
Management:
Organizations manage RPO through data replication strategies that ensure data consistency between primary and secondary systems.
Methods:
1) Synchronous Replication
This real-time synchronous replication method minimizes data loss by ensuring immediate transmission of data changes to secondary systems, making it ideal for applications with stringent RPO requirements, as data loss is nearly eliminated.
- Key Features:
- Real-time data synchronization.
- Zero data loss.
- Ensures strict data consistency.
- Automatic failover.
- Use Cases:
- Mission-critical applications (like financial systems) where data integrity and compliance is crucial.
- Applications such as online transaction processing (OLTP) systems.
- Geographically distributed setups, ensuring data consistency across locations.
2) Asynchronous Replication
This asynchronous replication method, replicates data changes with a slight delay, offering lower latency compared to synchronous replication. It suits scenarios where a minor data lag is acceptable.
- Key Features:
- Slight delay in data synchronization.
- Minimal risk of data loss.
- Lower latency compared to synchronous replication.
- Optimized for scalability, with large data volumes and growing demands.
- Use Cases:
- Reporting and analytics systems.
- Non-critical applications with acceptable data logs.
- Scenarios prioritizing performance over real-time consistency.
- Ideal for global distributed setups.
3) Backups and Snapshots
Regular backups and snapshots capture data at specific points in time, reducing potential data loss and contributing to meeting RPO targets.
- Key Features:
- Provides data recovery and restoration capability.
- Ensures data integrity and consistency during recovery.
- Offers point-in-time recovery options.
- Facilitates system recovery after critical failures.
- Use Cases:
- Disaster recovery scenarios.
- Ensuring business continuity during data corruption or loss.
- Compliance with data retention and regulatory requirements.
Data validation mechanisms ensure the accuracy and integrity of replicated data, maintaining alignment with RPO objectives.
2) Recovery Time Objective (RTO)
RTO defines the maximum acceptable downtime an organization can tolerate before recovering its systems and services.
Management:
RTO is managed through strategies that focus on swift system recovery and minimizing downtime.
Methods:
- Redundancy and Failover: Redundant systems and failover mechanisms reduce downtime by quickly switching to secondary or backup systems.
- Disaster Recovery Sites: These sites replicate data and applications to remote locations, ensuring quick recovery in case of a primary system failure.
- High Availability Architectures: Architectures designed for high availability distribute workloads across multiple systems, minimizing downtime.
While RPO focuses on data loss, RTO centers on system recovery time. Effectively managing both involves utilizing a combination of data replication methods, backup strategies, validation, and failover mechanisms to ensure data availability, consistency, and swift system recovery during disruptions.
Replication Mode Vs Operation Modes
In the context of SAP HANA’s high availability and system replication, understanding the distinction between replication mode and operation mode is crucial.
Replication Modes
Replication mode refers to how data is synchronized and replicated between the primary (source) system and the secondary (target) system in an SAP HANA high availability or disaster recovery setup. This mode significantly influences critical factors, including data consistency and latency.
Purpose
The primary purpose of replication mode is to determine the behavior of data transfer and synchronization between the primary and secondary systems. It outlines ‘when‘ and ‘how‘ changes made in the primary system get replicated to the secondary system, ensuring data consistency and availability.
Types of Modes
SAP HANA provides a various replication modes, such as:
- Synchronous replication (SYNC)
- Synchronous in-memory replication (SYNCMEM)
- Synchronous full replication (FULL)
- Asynchronous replication (ASYNC)
These replication modes play a pivotal role in defining factors such as data consistency guarantees, replication latency, and the impact on system performance. To gain more in-depth understanding of these replication. modes you can explore this blog.
Operation Modes
Operation modes in SAP HANA replication, refers to the state or configuration of an SAP HANA system that determines its specific role in an HA or system replication setup.
Purpose
Operation mode defines how a particular SAP HANA system behaves in response to various situations, such as normal operation, system failover, or system takeover. It dictates whether a system is in a read-only state, read-write state, or standby state.
Types of Modes
SAP HANA provides a variety of operation modes, such as:
- Delta Shipping
- Log_replay
- Logreplay_readaccess
These operation mode deals with the state and behavior of individual SAP HANA systems within a high availability or replication configuration. To gain more in-depth understanding of these operation modes you can explore this blog.
Both replication mode and operation mode concepts are essential for designing and configuring a robust and highly available SAP HANA environment.
SAP HANA Replication Strategies
A) Active/Active System Replication
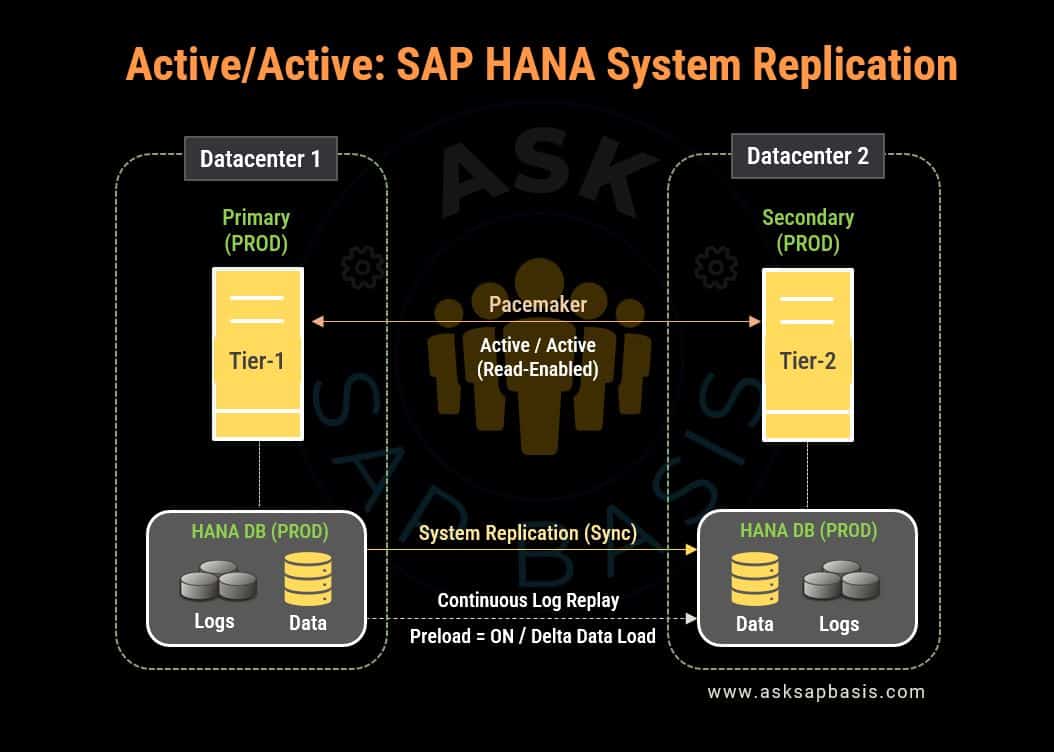
By implementing an active/active configuration for SAP HANA replication, you empower the secondary system with read-access capabilities.
- This configuration reduces the workload on the primary system, extending the secondary system’s capacity to efficiently handle read operations, all without the need to double its capacity.
- Consequently, this configuration makes the ports of secondary systems become accessible, allowing for read operations. This enhanced accessibility empowers the secondary system to efficiently handle read-intensive tasks, leading to a more balanced distribution of workloads. As a result, the performance of SAP HANA system is elevated, through improved load balancing.
- To enable active/active functionality, use “logreplay_readaccess” operation mode. This mode not only facilitates rapid takeovers, but also reduces the necessary bandwidth during continuous operations. Morever, it provides support for various replication modes (including SYNC (with or without the full sync option), SYNCMEM and ASYNC), thereby adding flexibility to system operations.
- Its important to note that both the primary and secondary systems must share the same SAP HANA version for implementing “logreplay_readaccess” operations.
B) Active/Passive System Replication
In Active/Passive HANA system replication, the primary system actively manages the live transactions, while the synchronized secondary system remains on standby host.
- Unlike an active/active configuration, the secondary system is restricted from SQL querying or read-access until it assumes control in the event of primary system failure.
- When failure occurs, the secondary system becomes active, ensuring the preservation of data integrity and a significant reduction in downtime.
- This approach, simpler to manage as compared to active/active replication, plays a crucial role for organizations that prioritizing failover readiness and operational stability.
In addition to these standard SAP HANA replication configurations, where it replicates all data to the secondary system, you can also configure multi-tier and multi-target system replication. These advanced replication configuration offer enhanced flexibility and strategic advantages for maintaining high availability and data redundancy.
Both multi-tier and multi-target system replication setups extend capabilities beyond the conventional model, enabling organizations to tailor their data replication strategies to their precise requirements.
C) Multi-Tier System Replication
The concept of multi-tier system replication involves actively maintaining multiple synchronized copies of the system. These copies are distributed across different tiers or layers and they often reside in distributed locations or distinct data centers.
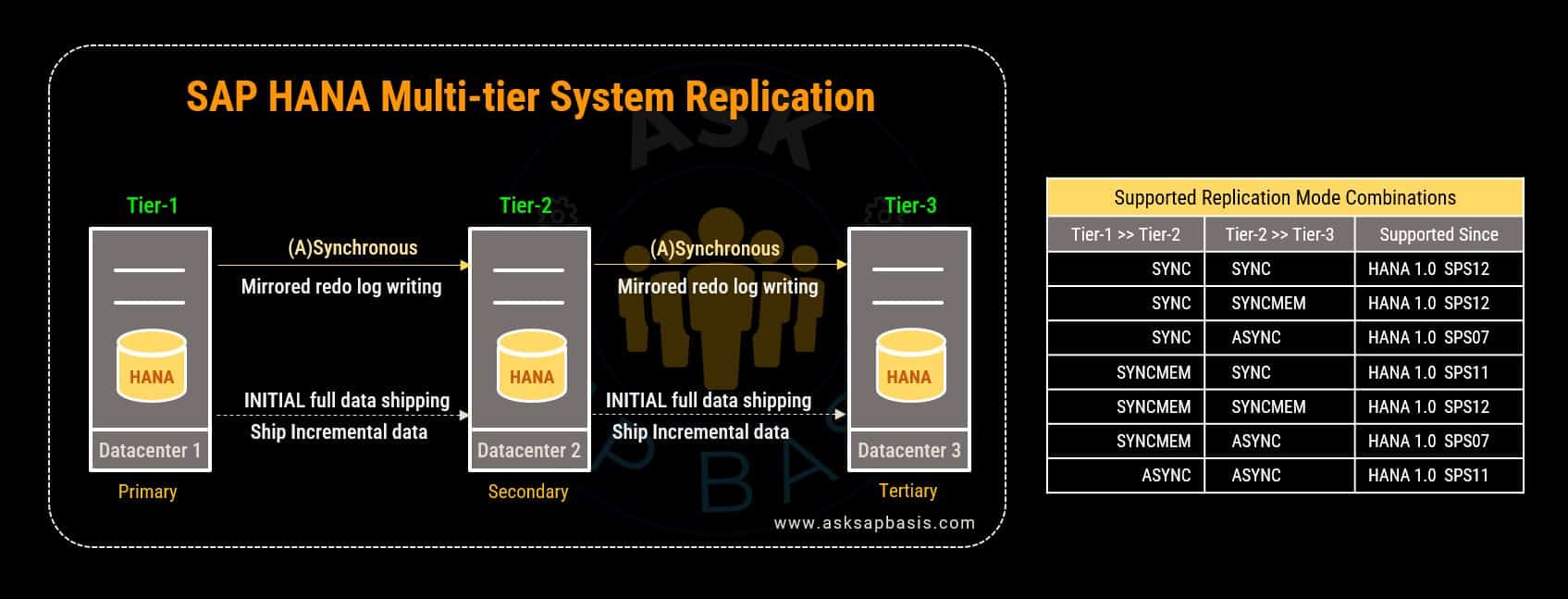
- The primary objective of this approach is to actively enhance system availability, bolster resiliency, and fortify disaster recovery capabilities.
- Within this framework, you can implement varying levels or tiers of data replication, either synchronous or asynchronous, tailored to meet specific business requirements.
- In this multi-tier scenario, a primary system (tier 1) operates in one data center, while a secondary system (tier 2) as a failover contingency in another data center. Additionally, a supplementary tertiary systems (tier 3) are strategically placed in diverse geographic locations to ensure comprehensive disaster recovery.
- SAP HANA enables the configuration of a multi-layered data redundancy approach using replication mode. The primary and secondary tiers handle the immediate replication, while adding tertiary tier replication enhances safe guarding. This ensures seamless data flow, improving fault tolerance and performance.
- This configuration establishes a chain of replication, facilitating the seamless flow of data across different tiers, thereby strengthening the overall system’s robustness.
- These replication modes also enable precise data distribution across tiers, optimizing resources and reducing latency for a responsive multi-tier system, while simultaneously establishing data redundancy, distribution and management. Strategic configuration strikes a balance between data availability, resilience and performance.
- You can gain a deeper understanding and explore use cases by following this link.
Key Benefits:
- Enhanced High-Availability: Facilitates geo-clustering between a primary data center and geographically remote data centers, creating a highly available system and minimizing downtime during failures.
- Disaster Recovery Capabilities: Supports robust disaster recovery by replicating to different locations.
- Scalability: Offloads read workloads from the primary system, improving scalability and performance.
- Flexibility: Tailors replication for different purposes, such as reporting and disaster recovery.
- Reduced Network Load: Distribution of replication data reduces overall network load.
- Isolation and Redundancy: Each tier acts as an independent standby, ensuring data integrity.
- Efficient Maintenance: Eases maintenance and upgrades by switching to lower-tier standbys temporarily.
- Compliance and Data Segmentation: Supports compliance needs and data governance.
- Hierarchical Data Distribution: Data flows through tiers in a structured way, catering to specific data usage patterns.
Multi-Tier Replication Scenarios
1) Performance–Optimized
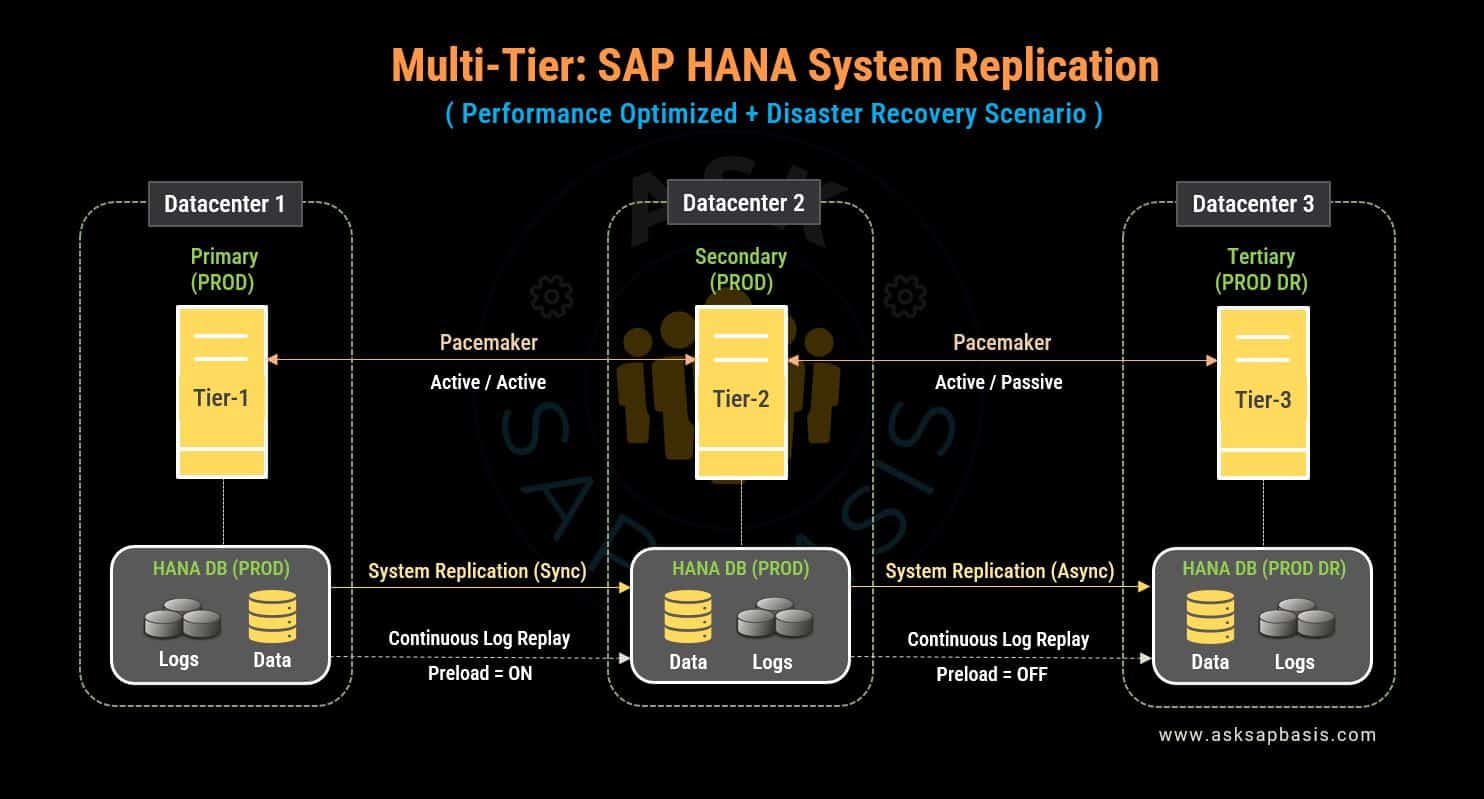
In a performance-optimized scenario, the primary SAP HANA system synchronizes with the secondary SAP HANA system. This configuration guarantees a near-zero recovery time objective (RTO) during both planned and unplanned outages.
- For optimal performance, it is recommended to host your SAP HANA instances within the data center. This prevents latency during synchronous replication mode.
- One key advantage of this performance-optimized setup is its proactive table preloading into memory, significantly reducing the synchronization between the primary and secondary databases. This ensures swift and efficient data transfer, resulting in a notably short takeover time in the event of a failure.
- Furthermore, this configuration offers the capability to grant read-access on the secondary system, enhancing load distribution and system performance.
- Implementing a third-party cluster-solution alongside SAP HANA replication enhances system reliability. This integration not only provides redundancy, but also detects failures and automates failure (using solutions like pacemaker) for crucial services and data. It actively monitors system health, efficiently distributes workloads, and allows customization to meet specific needs, ensuring continuous availability and minimal downtime.
In summary, this performance-optimized approach not only minimizes downtime but also optimizes data handling and access, ensuring robust business continuity.
2) Cost–Optimized
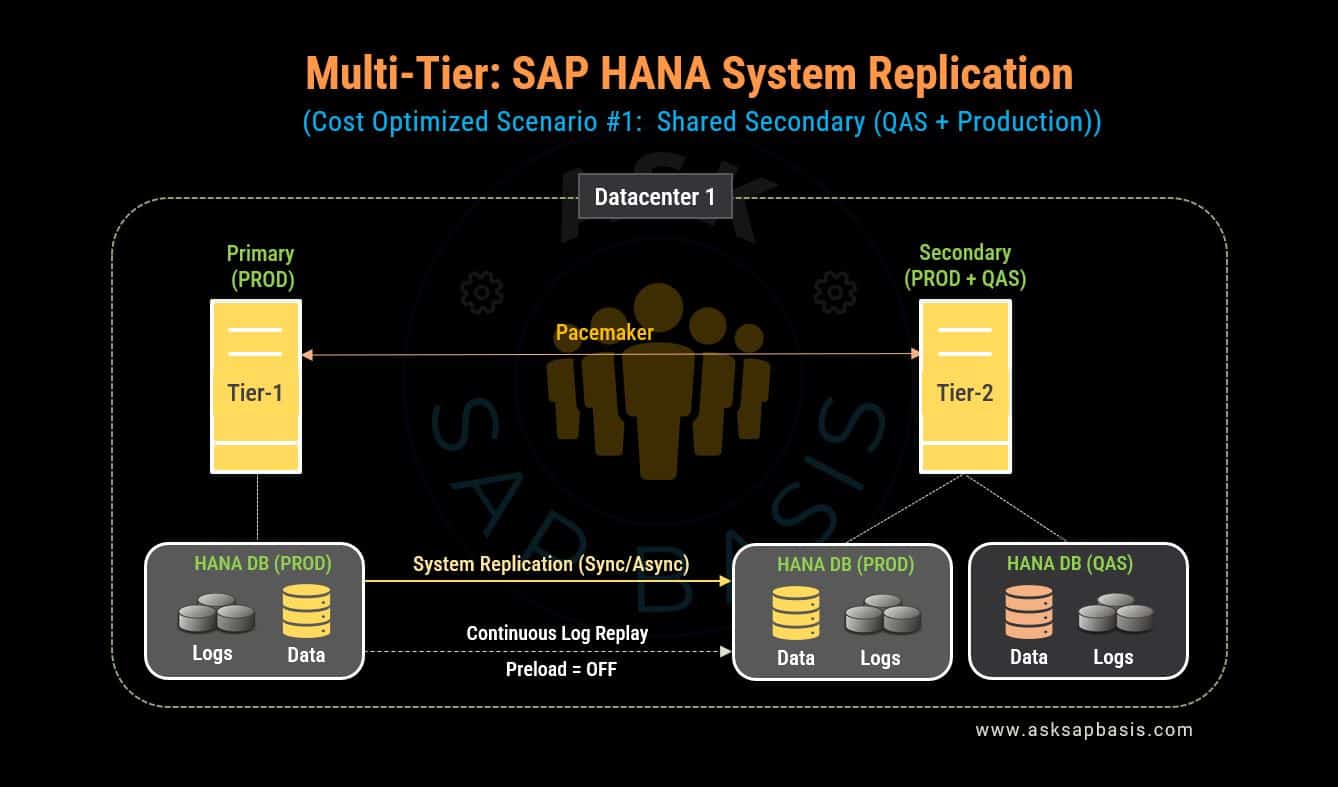
In a cost-optimized setup, you gain the flexibility to operate a non-replicated SAP HANA instance on the same secondary node where SAP HANA production system replication is active. This non-replicated database can serve as a development (DEV), testing (TST), or quality assurance (QAS) systems.
- The infrastructure resources on this secondary node are shared between the non-production and the replicated secondary SAP HANA system(PRD).
- The primary objective of this strategy is to minimize infrastructure and operational costs while ensuring high availability and disaster recovery for your SAP HANA database.
- A typical example of cost-optimized shared secondary approach is the MCOS (Multi-Component Operating System) system model.
- MCOS is an operating system design that focuses on modular architecture and organizes multiple components or modules within a single system. The concept aims to create a unified system that combines different components to enhance efficiency, reduce complexity, and improve overall performance.
- With this MCOS setup, you have the flexibility to concurrently run an ‘active’ non-productive instance, alongside the system replication of the production secondary system on the same host. However, running these multiple instances necessitates additional storage.
- In this configuration, data replication is directed to the disk, instead of memory (by disabling the preloading of column data). This differs from performance-optimized scenarios that use memory for replication.
- In the event of a failure, the non-production instance is gracefully stopped before the secondary node takes control of the production workload. This results in a significantly extended takeover time when compared to a performance-optimized configuration, highlighting the primary disadvantage of the cost-optimized scenario.
- While this deployment approach reduces overall costs, it comes at the expense of compromising the recovery time objective (RTO).
In the cost-effective MCOS setup mentioned above, both servers reside and operate within the same data center. However, it is crucial to be aware of a significant setback: this configuration lacks a robust backup or disaster recovery plan in case data center 1 faces serious issues.
Challenges and Solutions
As a result of this, the takeover processes not only extend in duration but also amplify the likelihood of delays in recovering and restoring the production system. To overcome these challenges and ensure uninterrupted business operations, consider enhancing this setup with a comprehensive disaster recovery (DR) plan.
Incorporating Remote DR
A robust disaster recovery plan should include the integration of a remote disaster recovery (DR) solution. This strategic addition guarantees business continuity even if severe issues affecting data center 1.
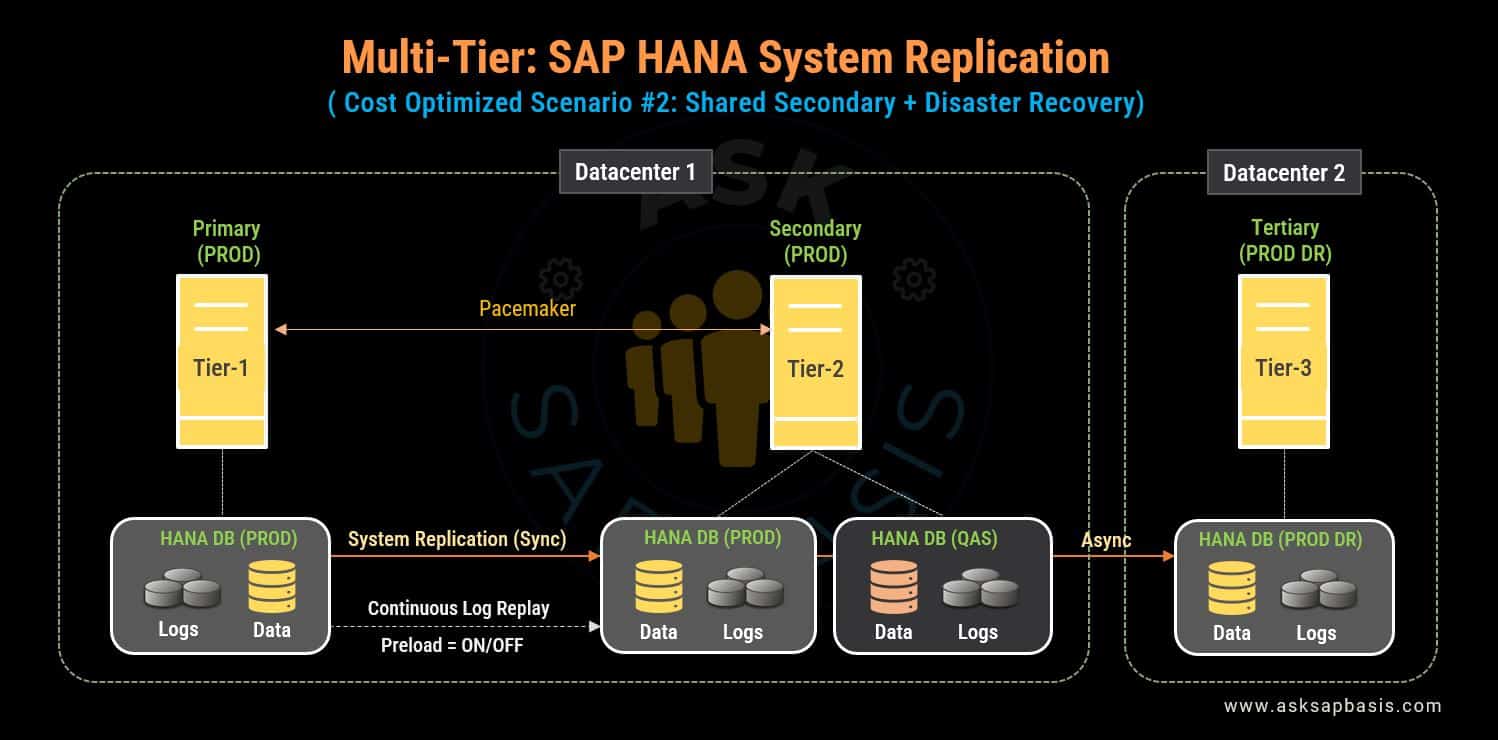
By introducing a comprehensive disaster recovery (DR) plan, ensures not only simplicity and transparency but also ensures overall robustness and resiliency. This added layer of preparedness and proactiveness assures business continuity while minimizing the risks associated with potential recovery and restoration delays.
To summarize, this approach strategically optimizes costs and maintains high availability and disaster recovery capabilities. Additionally, it offers flexibility by allowing the hosting of non-production smaller instances on the same node.
D) Multi-Target System Replication
In SAP HANA’s multi-tier scenario, data replication occurs sequentially. starting from the primary system and then progressing to secondary system and subsequently from secondary system to tertiary system.
With the release of SAP HANA 2.0 SPS 03 and subsequent versions, SAP HANA introduces a configuration for multi-target system replication. This configuration empowers a single primary system to replicate its data to multiple secondary systems.
Key Benefits:
- Load Distribution: Offloads read-intensive workloads from the source system, improving overall system performance.
- Flexibility: Accommodates evolving needs by adding or reconfiguring target systems as requirements change.
- Business Continuity: Maintains data copies across various geo-locations, enhancing business continuity and disaster recovery strategies. This helps in reducing the risk of data loss.
- Localized Access: Provides localized data access, improving query performance for regional or departmental needs.
- Customized Reporting: Enables targeted reporting and analytics without affecting the performance of the source system.
- Efficient Resource Utilization: Secondary systems can be used for specific tasks, optimizing resource allocation across the organization.
- Strategic Data Replication: Offers the ability to strategically place data copies where they are most beneficial for the organization.
- Enhanced High Availability: Facilitates higher availability through creation of new structures prior to discontinuing or replacing existing ones. It aims to minimize or eliminate downtime during the process.
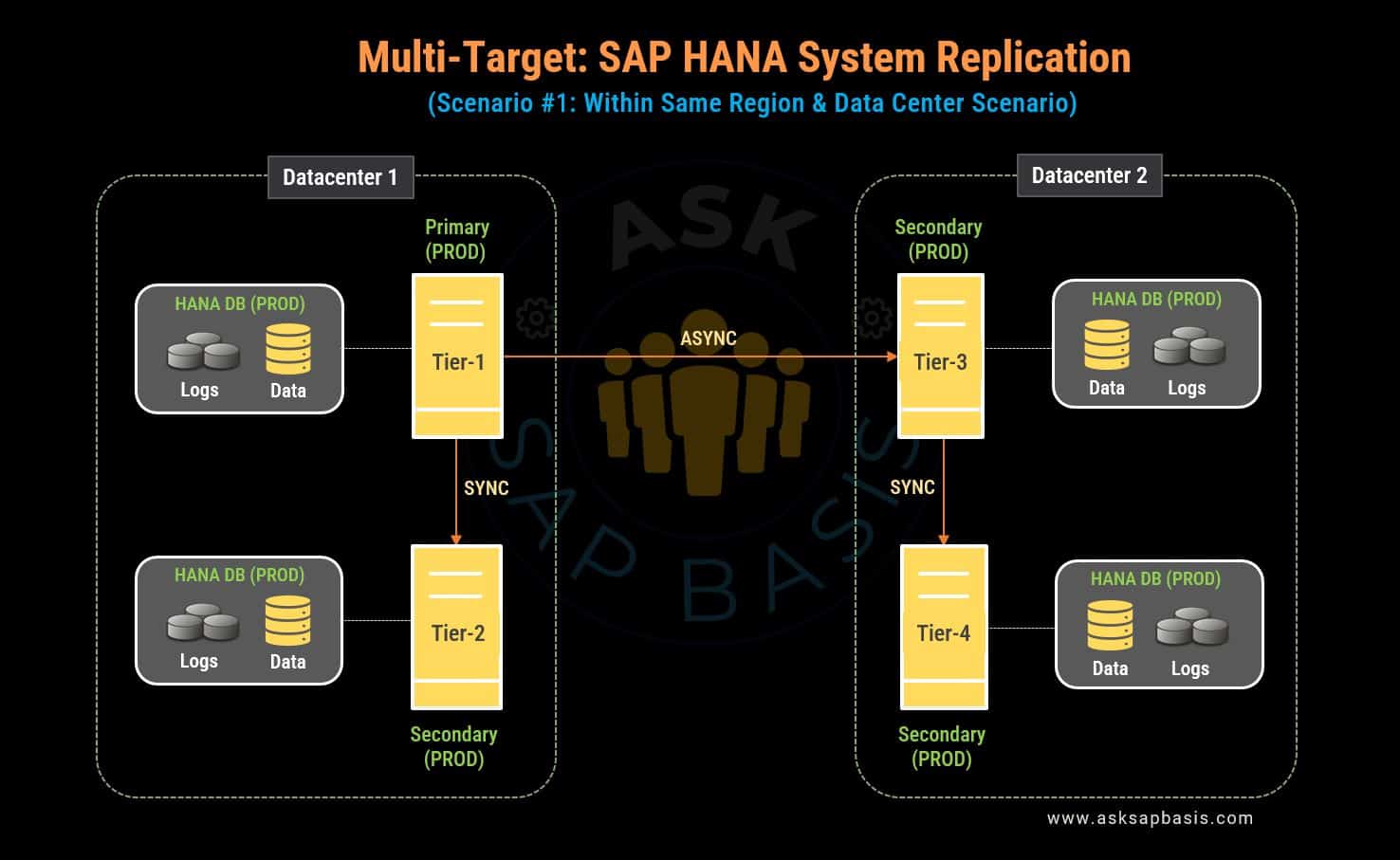
Replication Scenario #1
Multi-target system replication provides organizations with an effective solution for maintaining and optimizing data redundancy and availability.
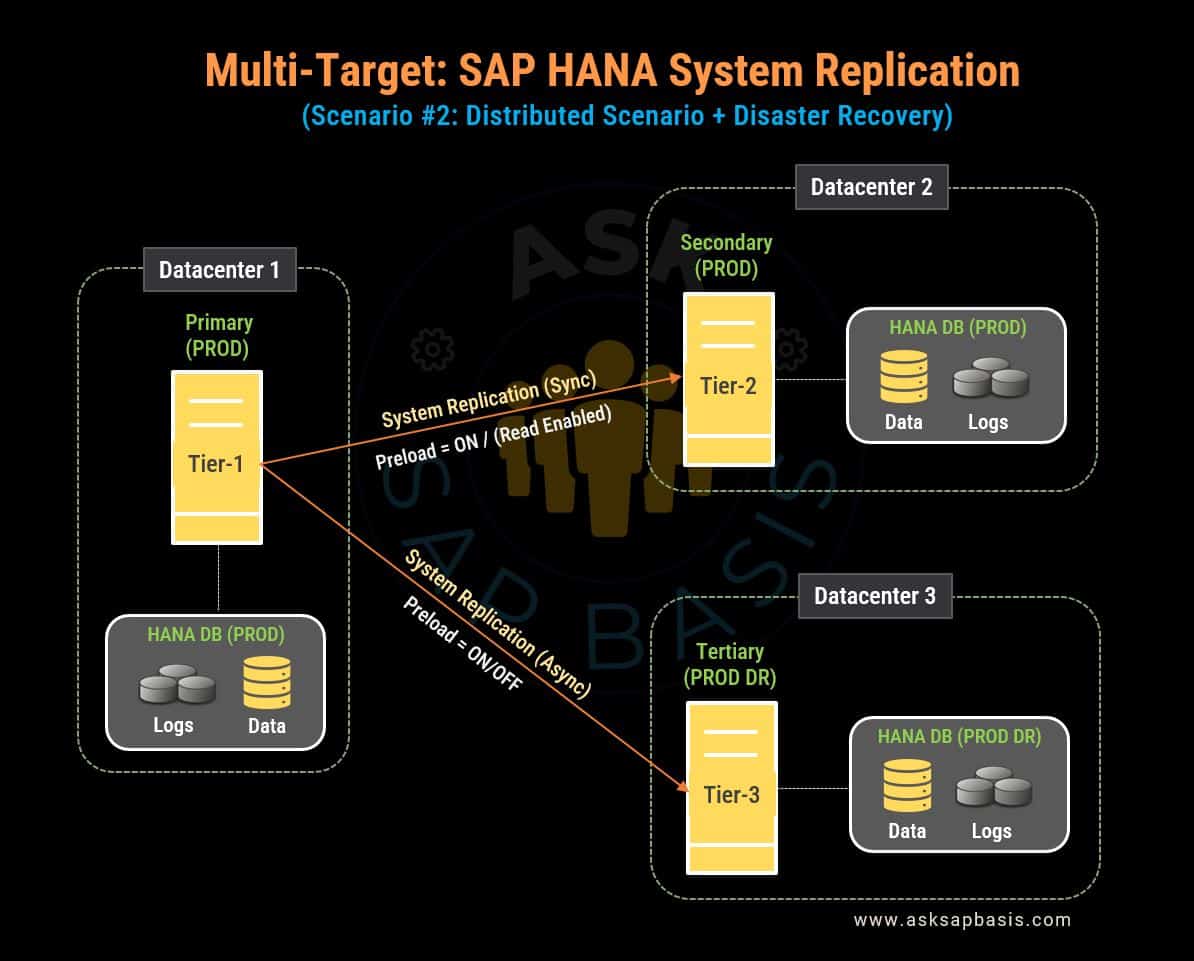
Replication Scenario #2
For instance, you can optimize one target for reporting and analytics while designating another as a disaster recovery solution. This approach ensures efficient data distribution to meet distinct operational needs.
Conclusion
In summary, SAP HANA replication is a critical pillar of modern data management, ensuring that businesses remain agile, resilient, and primed for success in an era where data is the lifeblood of decision-making. As technology continues to evolve, a firm grasp of these replication scenarios becomes increasingly indispensable, enabling organizations to not only survive but thrive in a data-driven world.
References
- How to configure multi-tier system replication
- SAP HANA System Replication Guide
- Active/Active System Replication, Configuration, Failover & Failback
Related Posts







