
SAP HANA High Availability: Strategy Guide 2025
Overview
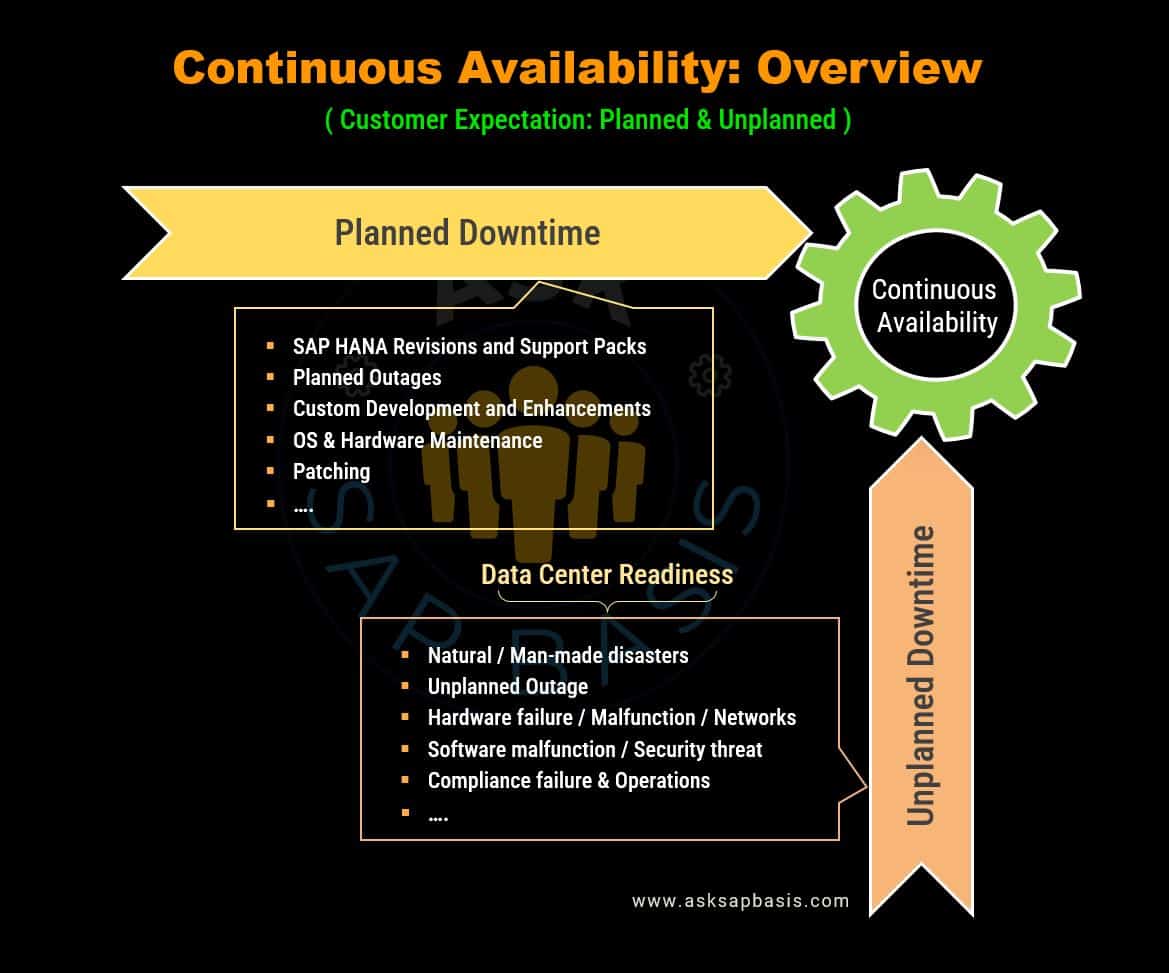
n today’s fast-paced business landscape, uninterrupted access to critical data and services is no longer a preference—it’s a necessity. The consequences of losing access to business-critical resources and services, such as SAP HANA, can result in substantial revenue loss. To tackle this challenge, SAP HANA has been purposefully designed for resilience, offering robust high availability solutions that encompass a wide array of recovery capabilities. These capabilities are not limited to addressing routine software errors but also extend to handling catastrophic site-wide disasters.
In this article, our mission is to delve into the intricacies of SAP HANA’s high availability support, with a special focus on fault and disaster recovery strategies. Our paramount goal is to equip businesses with proven techniques that not only ensure uninterrupted operations but also reduce risk and bolster the safeguarding of critical data and services against potential disruptions.
Discover how these proven techniques can help you maintain continuous operations and protect your business from unexpected disruptions. Let’s embark on a journey into the realm of SAP HANA High Availability and Disaster Recovery and learn how to fortify your system for maximum reliability.
SAP HANA High Availability
In the fast-evolving world of business, where downtime is simply not an option, high availability takes center stage. High Availability (HA) refers set of techniques, engineering methodologies, and design concepts aimed at achieving the goal of uninterrupted business continuity.
For businesses relying on SAP HANA, high availability is not just a luxury but a critical necessity. Imagine a scenario where a crucial SAP HANA system experiences an unexpected glitch, or worse, a complete outage. The consequences are far-reaching, ranging from financial loses to brand’s reputation. High availability solutions aims to prevent or minimize such disruptions.
Core Objectives of High Availability
An high-availability solution must accomplish four primary objectives:
- Eliminate data loss.
- Minimize downtime.
- Maintain data integrity and protection.
- Enable flexible configuration to accommodate evolving business needs.
SAP HANA’s Approach to High Availability
SAP HANA is designed to provide a robust high availability (HA) framework that empowers organization with comprehensive recovery measures. These measures extend across a wide spectrum of scenarios, encompassing everything from faults and software errors at full-scale disasters that could potentially lead to decommissioning of an entire data center.
SAP HANA achieves high availability through two fundamental principles:
1) Fault Tolerance
SAP HANA’s high availability and disaster recovery strategies are multifaceted, addressing a wide range of potential issues. One of the key components is fault tolerance.
This concept focuses on minimizing system disruptions caused by hardware or software failures, ensuring that your SAP HANA environment remains resilient and responsive. In other words, it eliminates vulnerabilities that could lead to single point of failures (SPoF). Therefore, it ensures that no single component or element in your IT infrastructure can bring the entire system down. SAP HANA’s fault tolerance are designed to create a robust and reliable system architecture.
To achieve fault tolerance, SAP HANA utilizes advanced technologies and redundancy measures. Redundancy involves having backup systems and components in place, ready to take over if the primary system encounters a fault. Fault tolerance is designed to offer continuous access to your business-critical data services.
2) Fault Resilience
SAP HANA, at its core, is engineered resilience. It stands as a reliable pillar for organizations seeking robust high availability solutions.
This concept prevents system failures, by focusing on the process of restoring operations following a fault-induced outage. It ensures that when issues do occur, your system can recover swiftly and with minimal impact on your ongoing business operations.
To achieve fault resilience, it has mechanisms in place to keep your operations running smoothly. It serves as the backbone of your business continuity strategy.
Disaster Recovery Concept
SAP HANA goes beyond fault tolerance and resilience; it emphasizes disaster recovery as a key part of business continuity.
Disaster recovery comes into play when there is a prolonged failure of data center or site. In this scenarios, SAP HANA ensures that operations can be efficiently and effectively recovered, allowing your business to bounce back even from the most severe setbacks. This facet of high availability ensures that your organization can weather even the most severe setbacks and swiftly return to operational normalcy.
Disaster recovery is not merely a reactive measure; its a proactive strategy. SAP HANA encourages businesses to engage in robust planning and preparedness effort. This includes the creation of comprehensive disaster recovery plans that outline the steps to take when catastrophe strikes. These plans encompass data backup strategies, offsite storage, and the allocation of resources for rapid response.
Core Objectives of Disaster Recovery
The core objectives of DR typically include:
- Data protection and recovery
- Minimize downtime
- Ensure business continuity
- Protect reputation and customer trust
- Compliance and legal requirements
- Resource allocation and prioritization
- Testing and improvements
- Cost management
- Communication and coordination
- Detailed documentation
In summary, SAP HANA empowers organizations to maintain business continuity in an ever-evolving IT landscape. Adaptability and security are at the core of SAP HANA’s HA framework, making it a reliable choice for businesses of all sizes.
High Availability Solutions
High Availability (HA) is a critical strategy in modern IT infrastructure. It involves incorporating redundancy in networks, hardware, and data centers to minimize the risks of single points of failure (SPOF). Redundancy acts as a safety net, ensuring uninterrupted access to critical components and mitigating business losses.
Embracing redundancy is a corner stone of maintaining maintaining business continuity, safeguarding an organization against unexpected disruptions.
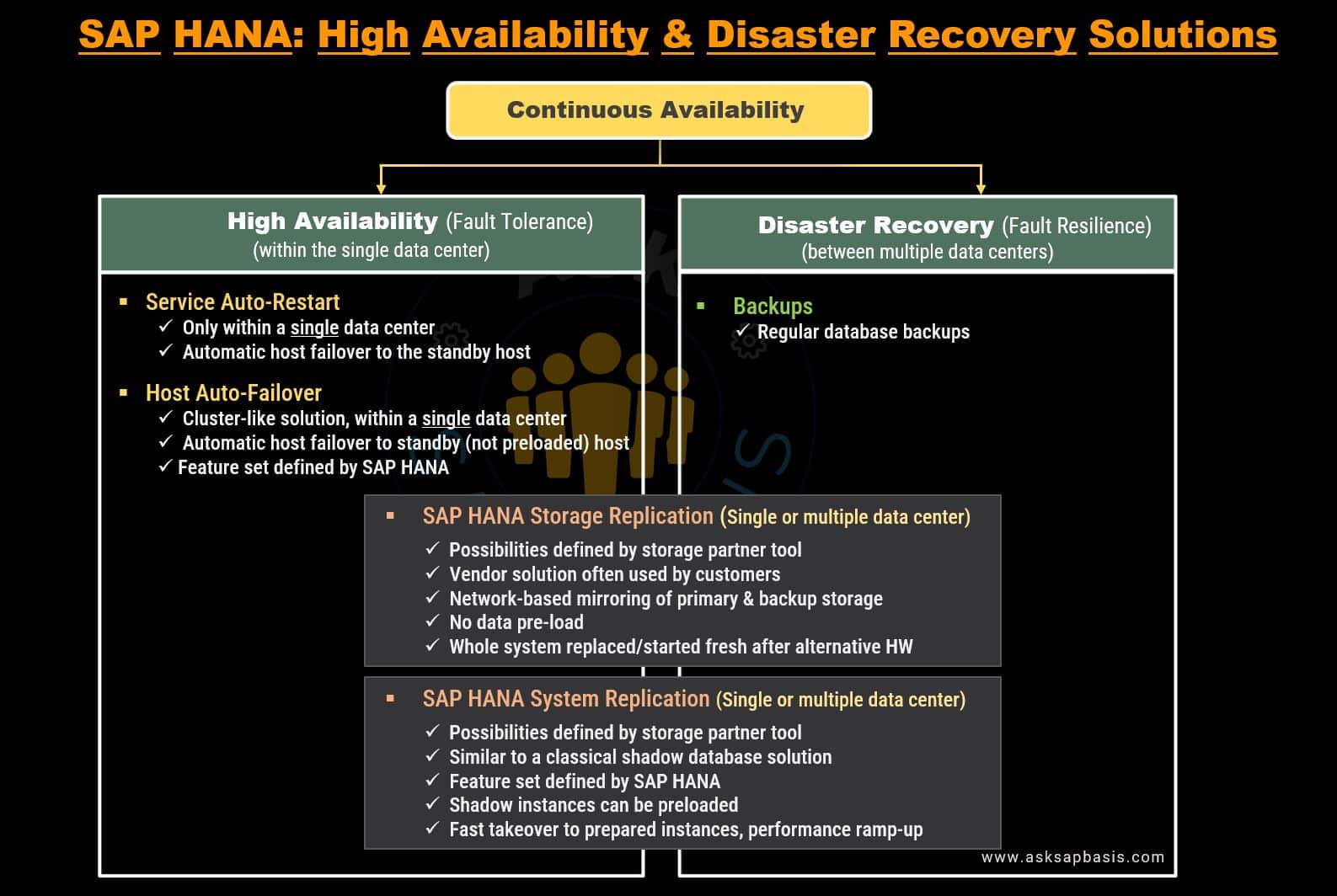
SAP HANA provides different high availability (HA) and disaster recovery (DR) solutions.
1) Service Auto-Restart
SAP HANA software includes an effective watchdog function, a mechanism programmed to monitor the health and stability of a system. It is integral to detecting and responding to failures, errors or abnormal conditions that may arise during the system operations.
The service auto-restart function in SAP HANA operates as a vigilant watchdog, providing automatic fault recovery capabilities.
- Proactive Fault Detection: The watchdog function actively detects and initiates the restart of any failed configured services (such as the index server, name server, or other service components) in SAP HANA. It remains on constant alert and automatically responds when a process is stopped, failed, or crashed, without requiring any human intervention.
- Automatic Recovery: When a failure is detected, the watchdog function springs into action, initiating an automatic restart of the affective service. This process is seamless, ensuring that data is promptly loaded into memory, and the service swiftly resumes its normal functions.
- Customizable Response: The actions performed by the watchdog service can be customized to meet specific requirements and scenarios. These actions may include automatically attempting to restart failed services, triggering alerts or notifications to system administrators, initiating recovery procedures, or executing corrective actions, as per organizations predefined protocols.
In essence, SAP HANA service auto-restart watchdog function acts as a vigilant guardian, diligently monitoring the well-being of the system. By promptly responding to anomalies, it ensure that the system continues to run smoothly, minimizing any potential downtime or disruptions caused by failures.
2) Host Auto-Failover
SAP HANA’s Host Auto-Failover is one of the powerful tool at your disposal. It is a local (“N+m”, where m is often 1) fault recovery solution that can compliment or serve as an alternative to system replication, offering a robust defense against potential disruptions.
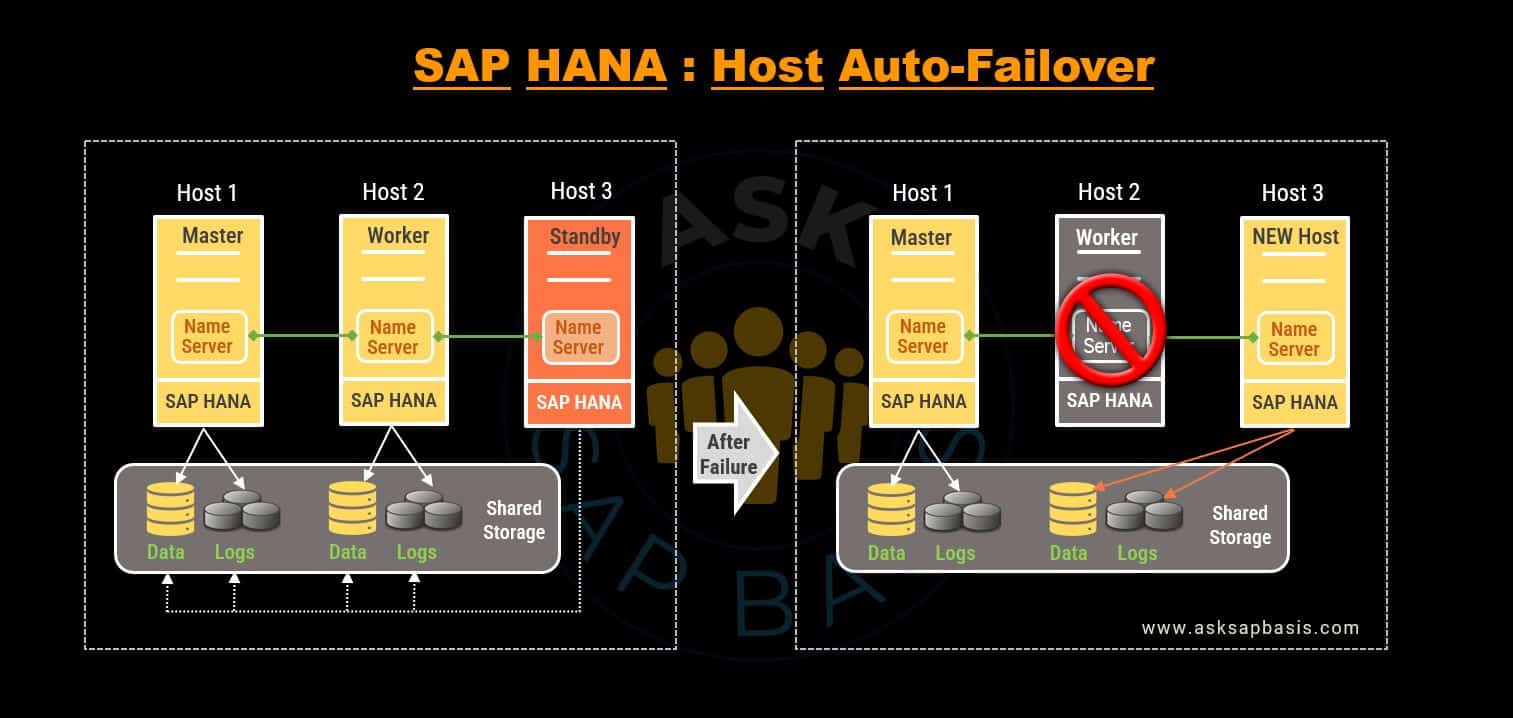
Concept
As the name implies “Host Auto-Failover”, operates at the host level. All services are moved to another host, where all services are intelligently relocated to another host in case of a failure. Importantly, its essential to note that the failure of single process (service) does not trigger an immediate failover. Instead, this process is seamlessly orchestrated as an integral part of SAP HANA, eliminating the need for any external cluster manager.
Enhancing Resiliency with Standby Hosts
To enhance resiliency, you can add and configure one or more SAP HANA hosts to operate in a “standby” mode. In this configuration, each host is connected to its own dedicated storage, with standby host having only the shared area mounted and no other additional resources.
Crucially, a shared storage network is a pre-requisite for this host auto-failover configuration. This network enables data and log files to be loaded from any server in the cluster. In this, each host is connected to its dedicated storage. Standby host has nothing mounted except for the shared area. In stand-by mode, the databases do not contain any pre-loaded data (unlike system replication) and as a result, do not accept any request or queries.
Failover Scenario
When the primary worker host encounters a failure, the standby host automatically assumes its role. This transition occurs when both the nameserver process (hdbnameserver) and hdbdaemon fail to respond to network requests, (indicating that the instance is stopped or the OS is completely down or powered off), the host is marked as “inactive”, triggering an automatic failover.
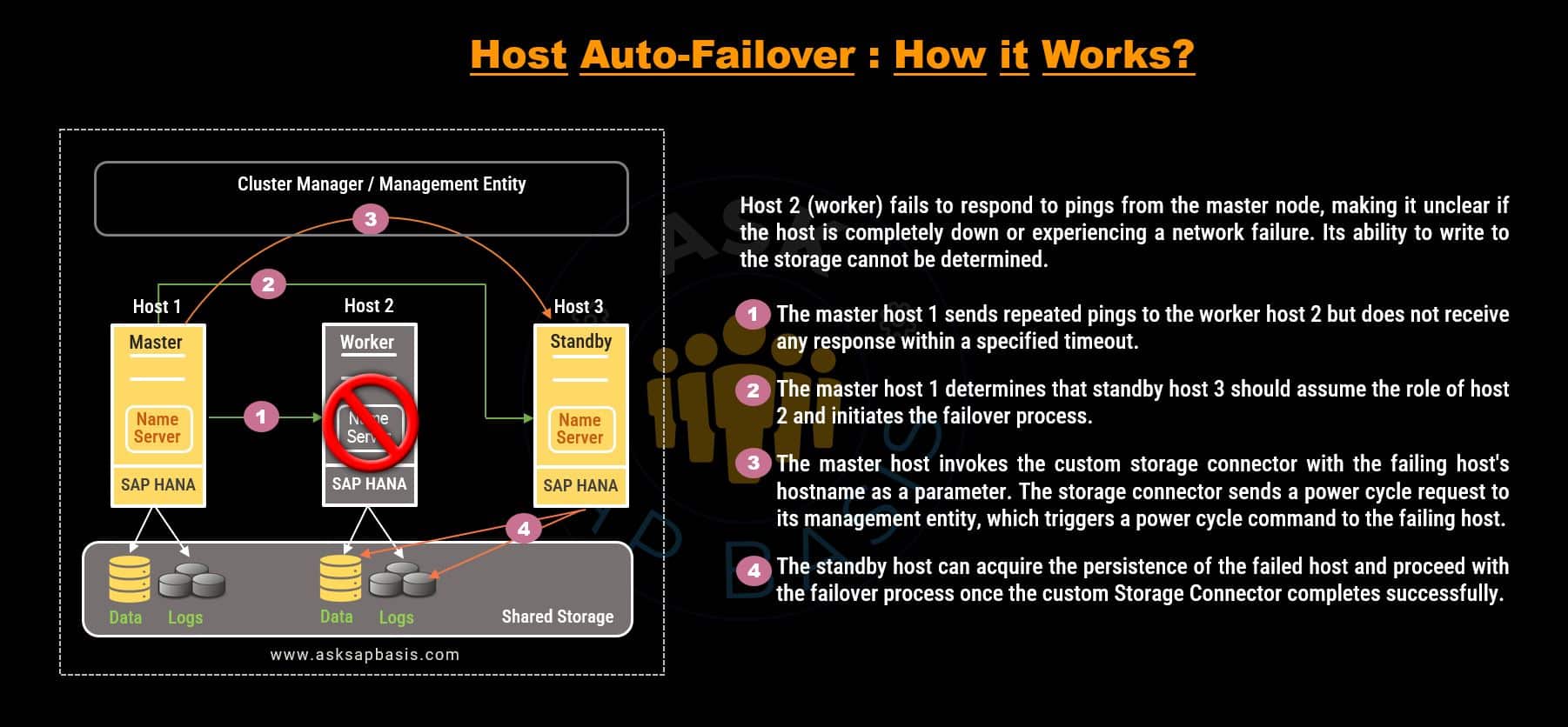
Ensuring Data Consistency: Role of Heartbeat and Fencing
SAP HANA employs two key capabilities to ensure data consistency during failovers:
1. Heartbeat
- Heartbeat process involves regular TCP communication to verify the active status of the primary host, ensuring it is ready or prepared to assume the master role.
- This communication can take place between nameservers, hosts, or the “hdbdaemon” using HANA’s internal communication protocol.
- Notably, the master “nameserver” serves as a cluster manager, overseeing the entire failover process within SAP HANA, eliminating the need for any third-party cluster software.
- During a failover, the standby host requires access to all DB volumes, to assume control of DB locks, preserving data integrity and preventing data loss. This is where I/O fencing plays a crucial role.
2. Fencing
- Fencing serves as a guarding of shared resources. It isolates a failed node & protects the shared pool or DB volumes.
- In rare cases, when the heartbeat cannot detect the liveliness of another host, such as split-brain situation, where communication between hosts is impossible. I/O fencing comes to the rescue. It ensures that the primary (failed) host loses write access to data and log volumes, preventing data corruption.
- In the event of an active (worker) host failure, a standby host automatically assumes it role. Since the standby host can take over from any primary host, it requires access to all the data & log volumes.
- This access can be achieved through shared networked storage, a distributed file system, or vendor-specific solution that leverage SAP HANA’s programmatic interface also known as storage connector API. These solutions dynamically detach and attach (mount) networked storage upon failure, enabling fencing & data access.
- Once the failed host is remediated, it can rejoin the system in a standby role, to re-establishing the failure recovery capability.
In essence, SAP HANA’s Host Auto-Failover is a sophisticated safety net, ensuring that your data operations remain resilient and your systems remain robust, even in the face of unexpected challenges. With its automated failover, seamless transition, and robust data integrity measures, it’s a vital tool for businesses seeking uninterrupted operations in today’s fast-paced digital landscape.
How Host Auto-Failover Work?
3) Backups
In a world of data management, where information is the lifeblood of every business, every transaction is a crucial heartbeat.
SAP HANA, a pioneer in in-memory technology, not only supercharges data processing but also ensures transaction durability. How does it achieves this?. It achieves this by persisting data changes, like inserts, updates, and deletions. SAP HANA fortifies itself against data loss, even if in the face of power outages. Morever, it stores these critical changes on disk, providing a multi-tiered defense for your data.
The Two Guardians of Data Durability
SAP HANA achieves this by persisting two types of data: Transaction Redo logs and Savepoints.
1. Transaction Redo Logs
- When a change is made to a record, then SAP HANA records it in a transaction redo log. Instead of persisting the complete data when the entire transaction is committed, SAP HANA only needs to persist the redo log, ensuring transaction durability.
- During an outage, the database can be restored to its most recent consistent state. This is achieved by replaying the changes from redo log, redoing the completed transactions, and rolling back the incomplete ones.
2. Savepoints
- Savepoints serve as the timekeepers of data efficiency. These periodic checkpoints are configured to save all modified data as pages. By default, savepoints occur every five minutes, but can be adjusted based on specific requirements.
- The primary purpose of savepoints is to expedite system restarts. During restarts, only the logs from the last savepoint position need to be processed, eliminating the need to start from the beginning.
- Savepoints are coordinated across all SAP HANA services and database instances to ensure transaction consistency. They usually write the older ones, but it is possible to freeze a savepoint at specific moments in time, creating snapshots, for future reference.
- Snapshots can be replicated as full data backups, allowing the database to be restored to a specific point in time, especially valuable in situations involving data corruption. In addition to data backups and snapshots, smaller periodic log backups, empowering you to restore the database to a specific point in time, particularly valuable when dealing with data corruption scenarios.
Delta Backups and Enhanced Recovery
- Apart from full data backups, delta backups can also be created, which only contain the data changes since the last data backup. There are two types of delta backups: incremental and differential backups.
- Incremental backups capture all changed data since the last full or delta backup, while differential backup encompasses all the data changes since the last full backup.
- Savepoints are typically stored locally, forming a fundamental part of crash recovery, while additional backups are stored on backup storage devices.
- In the event of crash, the database can be recovered without any data loss by utilizing the most recent savepoint, and replaying the latest logs. However, in cases, where a crash results in local storage corruption, its possible to restore the database using the data backup (or last snapshot) and log backups, although with some data loss.
Remote Backups: Strategic Disaster Readiness
For robust disaster preparedness, regularly shipping backups to remote locations via network or couriers is a straightforward and cost-effective approach. However, the effectiveness of this strategy, in terms of Recovery Point Objective (RPO), depends on the frequency of backups and the chosen shipping method, with timelines varying from hours to days.
In the dynamic landscape of data management, SAP HANA’s backup strategies serve as your stalwart guardians, safeguarding your data’s integrity and ensuring that your business can weather any storm with minimal downtime and data loss.
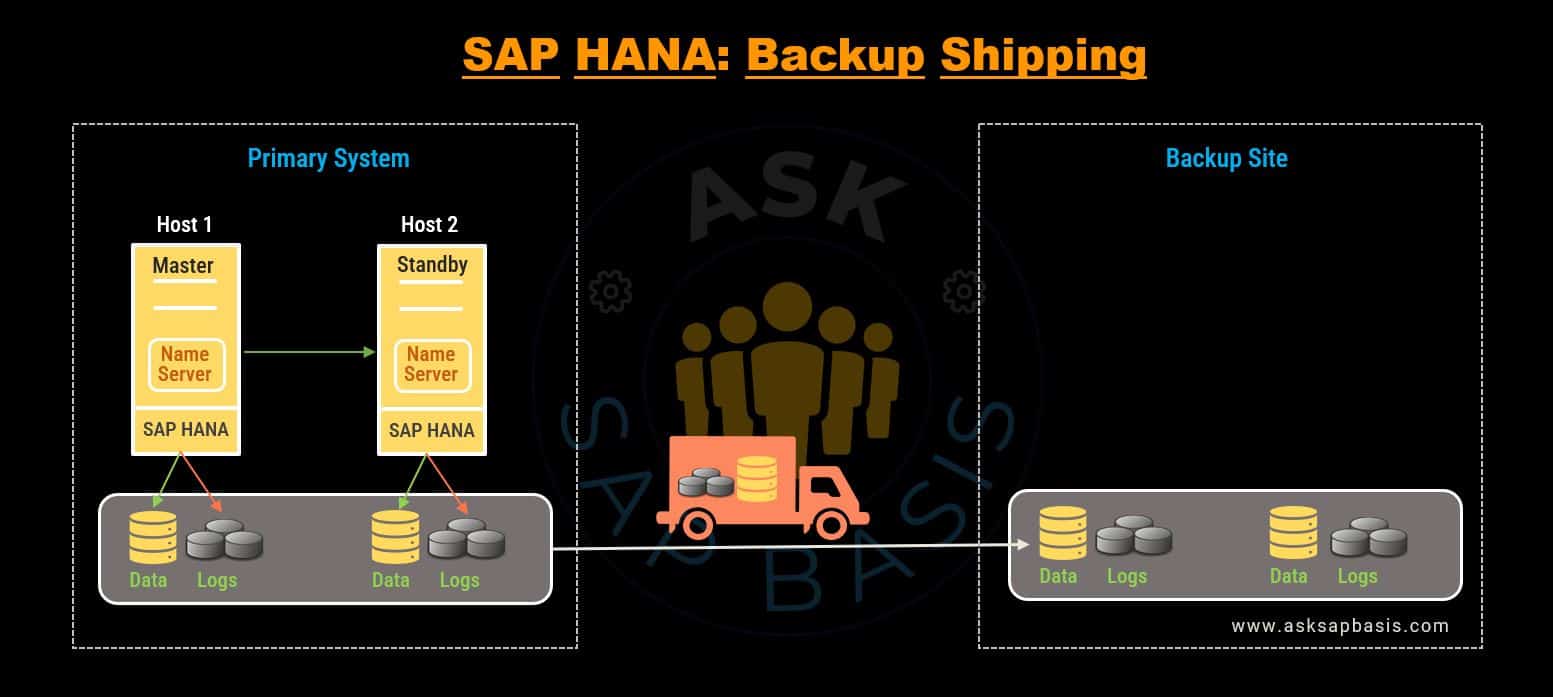
4) Storage Replication
Ensuring the availability and integrity of your data is paramount. Storage replication emerges as a powerful strategy, creating redundant copies of data in a secondary storage system to safeguard against hardware failures or system disruptions.
One of the limitation or setback of using backups, is the inherent possibility of data loss between the time of the last backup and the occurrence of the failure. To bridge this gap, organizations turn to continuous replication of all persistent data, ensuring that no data is left unprotected.
Continuous Replication with Storage Replication
- Storage replication empowers organization to maintain synchronized copies of their SAP HANA database on secondary storage systems, guaranteeing uninterrupted availability.
- This replication process operates at the storage level, independent of the SAP HANA system. It replicates data blocks from primary storage to secondary storage, and its typically facilitated by storage-level technologies like SAN (Storage Area Network) or NAS (Network Attached Solutions).
- Importantly, it is agnostic to the application or database being used and can serve broader purposes beyond SAP HANA.
Two Paths of Replication
1. Synchronous Replication
- In synchronous replication, data transactions are instantly and consistently replicated between primary and secondary storage.
- In this, SAP HANA transactions are considered complete only when the locally persistent transaction logs has been successfully replicated to the remote or secondary location. This meticulous approach ensures data consistency and reliability, and reduces data loss.
- However, its important to note that synchronous replication can introduce additional latency, as the transaction must wait for the replication to complete. This may have an impact on impact on the overall system performance.
- Synchronous replication solutions are best suited when the primary and secondary systems are located within a relatively short distance, typically no more than 100 kms apart.
2. Asynchronous Replication
- Asynchronous replication take a different approach, allowing for a certain waiting time between the data changes made in primary system and their replication to secondary system. So there is no immediate data synchronization here.
- In this scenario, the primary system commits transactions by writing them to log files and continues to send redo logs asynchronously to the secondary system without waiting for the acknowledgement or confirmation.
- This approach offers higher performance and lower latency compared to synchronous replication. However, there is slight data loss, if the failure occurs before the changes are replicated.
- Asynchronous replication solutions are well-suited for longer distances between locations, as the writing of redo log files does not significantly impact the latency times.
5) System Replication
System replication presents a robust and reliable high availability (HA) solution for SAP HANA, offering an alternative approach to safeguard your data.
- This method involves replicating the entire SAP HANA system, encompassing both data and system configuration. The key objective is to maintain continuous live replication, effectively synchronizing the SAP HANA database with a secondary location. This secondary site can reside either within the same data center or at a remote secondary or disaster recovery (DR) site.
- All data that is replicated to secondary location or site is pre-loaded into its memory. To optimize efficiency, all data are logs are compressed before shipping. This compression contributes to achieving a very short recovery time objective (RTO) and seamless compatibility with all SAP HANA hardware partner solutions.
- System replication operates at the application layer, focusing on replicating critical data and system-specific information necessary for failover. It plays a vital role in maintaining consistency between the primary and secondary systems.
- System replication employs an “N+N” strategy where a secondary standby SAP HANA system is actively maintained, featuring an equal number of active node as the primary system.
- In the event of failover, the secondary site can take over seamlessly without the need for restart, assuming the role of the primary DB straightway. In standby mode it does not accept any requests or make any changes to the DB.
- If the system is configured in active/active (read-enabled) setup, the system can handle queries and reporting tasks without interfering the primary system.
In the world of SAP HANA, system Replication stands as a formidable guardian, ensuring reliability, high availability, and uninterrupted data integrity. It provides a robust alternative to conventional HA solutions, offering peace of mind in the face of potential disruptions.
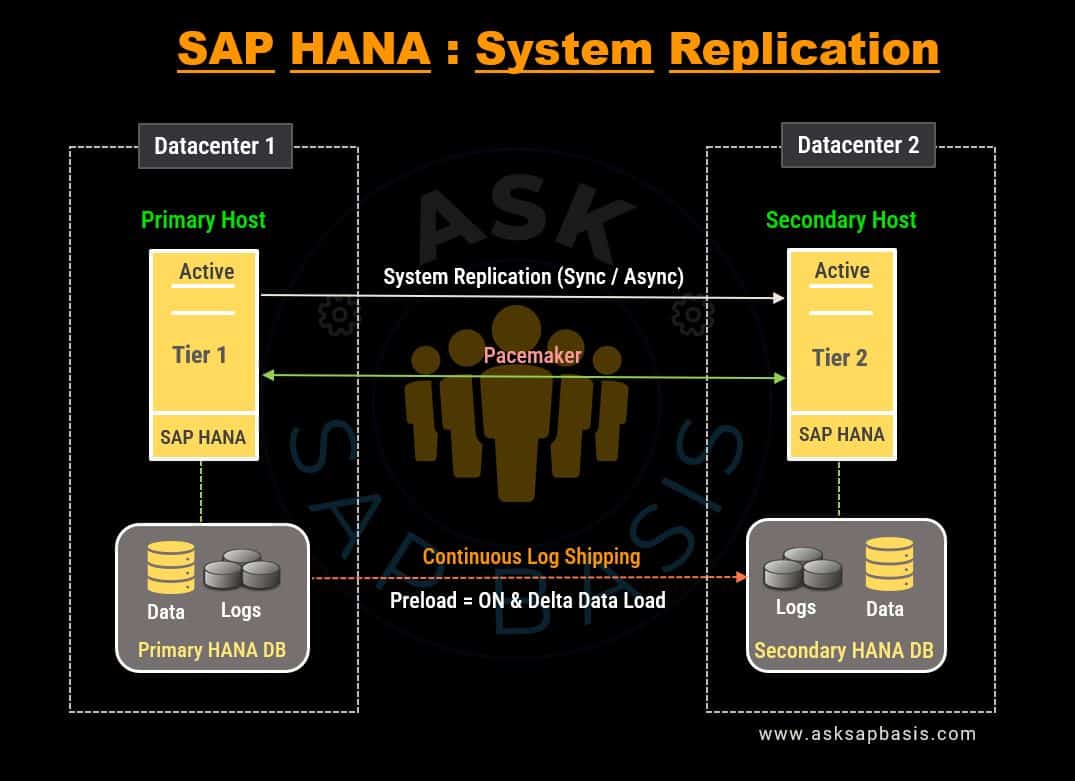
Replication Modes
Replication modes, serves as the cornerstone of data synchronization and the maintenance of consistency between primary and secondary systems. SAP HANA offers various replication modes, each tailored to specific operational requirements:
1. Synchronous In-Memory (SYNCMEM) Replication
- This modes serves as the default replication mode.
- In SYNCMEM replication, the secondary system promptly sends an acknowledgment to the primary system upon receiving data in its memory.
- The key benefit of this mode is a shorter transaction delay, resulting in enhanced system performance.
2. Synchronous (SYNC) Replication
- Unlike SYNCMEM, in SYNC replication, the primary system does not commit a transaction until the secondary system sends an acknowledgment back as soon as the data is received, and logs are persisted on disk.
- While this mode guarantees immediate consistency between both systems; it introduces a transaction delay due to data transmission and disk persistence in the secondary system.
3. Synchronous FULL Sync Replication
- This replication mode was introduced with support pack 08 (SPS08). It serves the purpose of providing complete data protection, ensuring ‘zero‘ data loss.
- This “full sync” option is typically employed during the initial synchronization process between the primary and secondary systems.
- In this mode, the entire database is copied from the primary system to the secondary system, establishing an identical copy. Once the full sync is completed, the system seamlessly transitions to the ongoing delta synchronization mode, where only the changes or delta updates are replicated from primary to secondary system.
- This full sync option is particularly useful when setting up a new secondary system or after a major disruption that requires complete resynchronization.
4. Asynchronous (ASYNC) Replication
- In this mode, the primary system sends redo logs to the secondary system without any delays.
- Transactions are committed on the primary system as soon as the log write is successful, without waiting for acknowledgement from the secondary system.
- This mode offers enhanced performance and improved efficiency, by eliminating the need to wait for log I/O on the secondary system, ensuring data consistency. However, it is more vulnerable to the risk of data loss.
Operation Modes
Operation modes, also known as availability or system mode. It is concerned with the state and behavior of the system during various scenarios, such as normal operations, failover and system recovery.
In addition to replication modes, SAP HANA offers three operation modes that dictate the behavior of the system in various scenarios, such as normal operations, failover, and system recovery.
1. Logreplay
- This is the default operation mode, where redo log shipping continuously occurs after the initial configuration of system replication with full data shipping.
- The redo log is replayed continuously upon arrival, rendering it unnecessary during take over. This means, the secondary system can immediately take over if the primary system fails.
- As this operation mode eliminates the need for delta data shipping’s, the data transferred to the secondary systems is significantly reduced.
2. Logreplay_readaccess
- This mode is essential for enabling replication to secondary system that is configured active/active (read-enabled).
- This mode is synonyms with logreplay in terms of continuous log replication, redo log replays on secondary system, as well as the initial full data shipping and the takeover.
3. Delta Shipping
- In this mode, system replication is established, where in addition to continuous log shipping, a periodic delta log shipment occur (typically every 10 mins by default).
- The secondary system stores the shipped logs, without replaying them until it needs to take over. During take over, the redo logs must be replayed up to the most recently arrived delta data shipment.
In summary, SAP HANA’s system replication offers robust and flexible solutions for high availability, ensuring data consistency and minimizing downtime in critical scenarios. These replication and operation modes are your strategic allies in the quest for data integrity and system reliability.
Advantages and Limitations
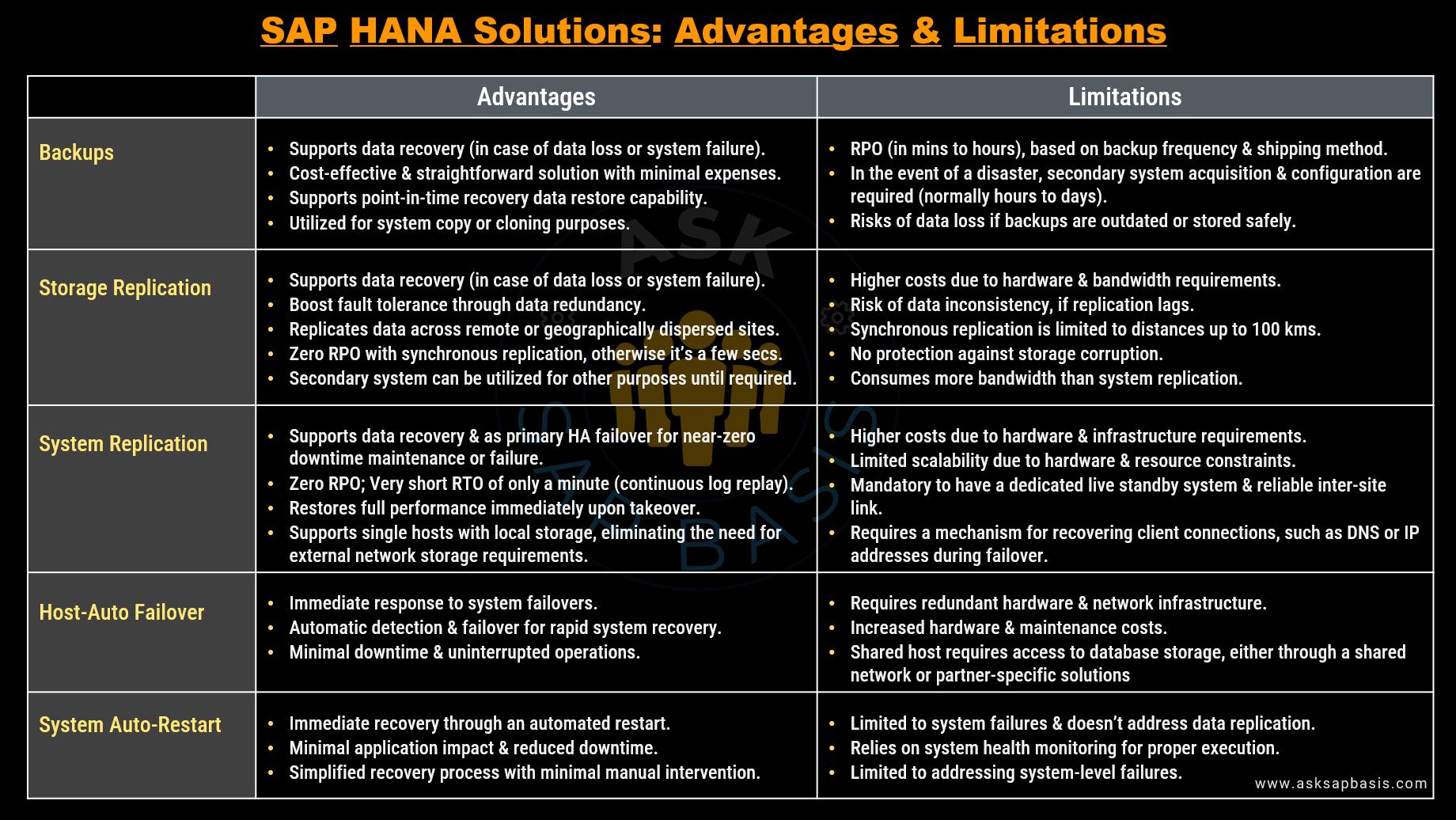
Host Auto-Failover Vs System Replication
| Factors | Host Auto-Failover | System Replication |
| Technology Used | Cluster-like solution in the same data center | Classical shadow database solution supported both in the same or multiple data centers. |
| Used for | High Availability | High Availability & Disaster Recovery |
| Architecture | "N+M" fault-recovery HA solution, with one or more standby nodes, with no preloaded data. | "N+N" HA & DR solution. Secondary standby system has same number of active nodes as primary system. Data is preloaded. |
| RPO | Zero | Zero with synchronous replication |
| RTO | Medium. May incur extended downtime | Low. Minimal Downtime |
| Scalability | Limited (Within Single datacenter only) | Highly Scalable (across Single or multiple datacenters) |
| Auto-Failover Method | Managed at application or host-level. The failover is not triggered by failure of single service. Failover is "internally" managed by SAP HANA nameserver. | Managed at system-level. Failover is done with "external" cluster management software provided by hardware vendors. |
| Data Pool | Single data pool using shared NFS or distributed file system. | Multiple data pools supporting single or multiple data centers. |
| Data Consistency | Heartbeat (regular TCP communication) and I/O fencing options utilized to isolate failed node. | Continuous replication with various replication and operation modes. |
| Multitenant Database Container Support | Supported at host-level | Replication of entire system; single tenant replication not supported. |
| Replication Modes | Not necessary as the disk is shared, and data consistency is already ensured. | Various replication modes supported: SyncMem, Sync, Async, & Full Sync. |
| Flexibility | Rigid | Secondary system can be utilized for QA purposes with an additional disk. |
System Replication Vs Storage Replication
| Factors | System Replication | Storage Replication |
| Technology Used | Software-based replication | Hardware-based replication |
| Replication Method | Replicates at entire system level | Replicates data at storage block level. |
| Functionality | Functions at application layer, replicating essential data & system-specific information for failover. | Agnostic to application & database being used & can be used for purposes beyond SAP HANA. |
| Failover Time | Very fast failover time | Relatively slower failover time |
| Data Integrity | Ensures data consistency across all primary and secondary system components. | Ensures data redundancy and protection against storage failures or corruption. |
| Impact on Performance | Very Minimal | Medium |
| Storage Independence | Dependent on underlying storage technology | Independent of storage technology |
| Licensing Costs | No additional licensing costs | May require additional licensing costs. |
| Administrative Complexity | Requires configuration and monitoring | Simpler configuration and management process |
| Downtime | Ensures zero downtime during upgrades and patching of SAP HANA. | Not applicable to storage replication. |
| Optimized Data Transfer | Uses compressed log stream for efficient data transfer. | Dependent on storage replication technology |
| Configuration | Simple setup using SAP HANA Cockpit, SAP HANA studio, or hdbnsutil | Setup dependent upon storage solution. |
| Preloading and Log Replay | Enables fast failover by preloading data and replaying logs. | Not Applicable |
| Read Access on Secondary | Allowing reading access on the secondary HANA system. | Typically not available on storage replica. |

