
SAP HADR: High Availability & Disaster Recovery 2025
Introduction
In today’s dynamic business landscape, the need for speed and uninterrupted availability has become paramount. Every second counts, especially for organizations operating round the clock. The repercussions of downtime can be severe, resulting in not only substantial financial losses but also irreparable damage to a company’s reputation.
SAP systems, being at the core of many enterprises, are particularly vulnerable to the adverse impacts of downtime. This article aims to provide you with a comprehensive grasp of two indispensable concepts: High Availability (HA) and Disaster Recovery (DR). These concepts serve as the bedrock of ensuring that your SAP system remains perpetually accessible and that your business is shielded from unexpected disruptions.
The primary goal of this article is to provide you with a comprehensive understanding of HA/DR basics. Armed with this knowledge, you will be better equipped to keep your business operations running seamlessly, even in the face of unforeseen catastrophic failures.
Overview
Assume a world where your business operations never stop, no matter what problems you face. High Availability and Disaster Recovery provide this assurance, serving as two indispensable pillars of a robust business continuity strategy.
Although the terms high availability (HA) and disaster Recovery (DR) are often mentioned together as HADR, but they are not the synonymous. Its crucial to understand the distinction between two, in order to effectively plan and manage potential risks.
- High Availability (HA) is primarily more of a technology design; Disaster Recovery (DR) is a program & a strategy.
- HA refers to a system configuration designed to ensure continuous operation and minimize downtime. It includes redundancy, failover mechanisms, and other measures that guarantee availability during hardware or software failures.
- DR outlines set of procedures to respond to disasters, whether they are natural or man-made. This involves data backup, restoration, recovery, and crisis management policies and procedures.
- In essence, HA ensures system availability; while DR empowers an organization to recover from the disasters and resume operations as quickly as possible.
- Both HA & DR are integral components of a comprehensive business continuity plan.
- HA does not replace DR.
- Both aim at preventing downtime and maintaining data integrity & productivity.
- HA & DR together work as part of good strategy.
- In scenarios where a High Availability (HA) or any IT environment experiences failure for an extended period of time, the Disaster Recovery (DR) environment and its associated recovery procedures become pivotal in re-establishing the system.
- HA & DR solutions
- Primary and secondary environments can be deployed in three ways:
- On-premise
- In Cloud
- Hybrid (combining both on-premise and cloud solutions)
- Primary and secondary environments can be deployed in three ways:
HADR Terminology
In the context of High Availability (HA) and Disaster Recovery (DR), understanding the terminology is crucial for implementing and managing these solutions effectively. In this section we will delve into the key terms and concepts associated with HA and DR to help you navigate this complex landscapes seamlessly.
High Availability (HA)
| Term | Terminology |
| Node | A node is a single machine (either physical or virtual) that collaborates with others in a group of servers to ensure highly available services. |
| Cluster | A cluster is a group of server working together to provide a highly available service. |
| Failover | Failover is a process of automatic transition to a secondary or backup system in the event of primary system failure. |
| Redundancy | Redundancy involves having multiple identical components within a system to ensure that the system can continue functioning uninterruptedly even in case of component failure. |
| Load Balancing | Load balancing distributes workloads across multiple servers to optimize resource utilization and prevent server overload. |
| Virtual IP (VIP) | VIP is a unique IP address assigned to a server cluster, redirecting traffic to an active server if a failure occurs. |
| Heartbeat | Heartbeat is a signal exchanged between servers in a cluster to verify their proper functioning. |
| Split brain | In a clustered environment, a split brain scenario occurs when nodes lose the ability to communicate effectively, causing them to operate independently. |
| Fencing | Fencing also referred as STONITH (Shoot The Other Node In The Head), actively prevent split brain situations by isolating malfunctioning nodes or shutting them down, safeguarding against data loss. The failed node remains separated until it is fixed and can synchronize with the cluster effectively. |
| Quorum | Quorum represents the minimum number of active nodes required for a clustered environment to operate correctly. Each node has a vote, and if the number of votes drops below the quorum value, the cluster ceases operations to maintain integrity and availability of the system. |
Disaster Recovery (DR)
| Term | Terminology |
| Backup | The process of restoring data from a backup |
| Restore | A backup is a copy of data that can be restored in case of data loss or corruption. |
| Backup Window | Backup Window is the designated time frame during which backups are performed. |
| Hot Site | Hot site is a fully operational backup site capable of taking over in case of a disaster. |
| Cold Site | In contrast, a cold site lacks the necessary equipment and infrastructure to function independently and requires quick upgrades to become operational. |
| Warm Site | Warm site is a backup site that has some equipment and infrastructure, but still needs further work to achieve full operational readiness. |
Common Terminology for HA & DR
| Term | Terminology |
| Primary Site | In the SAP HADR setup, the primary site or system serves as the main source of data and applications, maintaining continuous data replication to the secondary system. |
| Secondary Site | The secondary system acts as a standby system or site, holding a synchronized copy of data from the primary system and taking control incase of failure or planned maintenance. |
| Data Replication | Data replication is the process of copying data from one location to another for backup and disaster recovery purposes. |
| Disaster Recovery (DR) Site | In SAP HADR, a disaster recovery site is a separate datacenter or geographically distinct location where the secondary system resides, ensuring data resilience and business continuity in the face of major disasters. |
| Failover | Failover is the process of switching from a primary to a secondary system or site in the event of a failure. |
| Testing | Testing is the process of validating the effectiveness of HA and DR solutions through simulations and other tests. |
| Recovery Point Objective (RPO) | RPO defines the maximum acceptable data loss in the event of a disaster. |
| Recovery Time Objective (RTO) | RTO signifies the maximum allowable time for system recovery following a disaster. |
| Business Continuity Planning (BCP) | BCP is the process of creating a plan to ensure the continuity of critical business functions in the event of a disruption or disaster. |
High Availability (HA)
High Availability (HA) isn’t just a buzzword; it’s a critical component that ensures uninterrupted operations. HA is a technology design and implementation approach that prioritizes system resilience, minimizes disruptions, and guarantees business continuity.
The Essence of High Availability (HA)
HA is all about designing systems that are robust, fault-tolerant and capable of withstanding disruptions. It incorporates redundant configurations, load-balancing, and real-time monitoring to swiftly identify and rectify potential issues. The principle goal of HA is to minimize or mitigate the impact of downtime. It ensures that services remain accessible even in the event of hardware failure, software glitches or routine maintenance.
One of the HA’s primary mechanisms is “failover”, which ensures automatic transition to a secondary system if the primary system encounters any issues. Morever, HA eliminates all single points of failure from your infrastructure, ensuring maximum uptime for critical systems.
A successful strategy aims to optimally balance technical capabilities, infrastructure costs, business processes, and service level agreements (SLAs). Its about crafting a plan that not only guarantees high availability but also work efficiently.
Measuring Availability
Availability of system is calculated as: Actual time x Expected time x 100%. The result is often expressed in terms of “9’s”, representing annual uptime in minutes, or downtime in minutes. For example:
| Number of 9's | Availability % | Total Annual Downtime |
| 1 | 95% | 18 days |
| 2 | 99% | 3 days, 15 hours |
| 3 | 99.9% | 8 hours, 45 mins |
| 4 | 99.99% | 52 minutes, 34 seconds |
| 5 | 99.999% | 5 minutes, 15 seconds |
High availability is vital for mission-critical and business-critical systems such as online banking, e-commerce, emergency response systems, and internet servers. Even brief interruptions or downtime can result in significant consequences.
Essential Qualities of HA Architecture
The following are the some essential qualities that the HA architecture must posses:
- Redundant Hardware: Without redundant hardware, a crash means no requests can be served until the server is restarted. This leads to downtime. To prevent this, a high-availability architecture must include backup hardware like servers or server clusters. These backups can take over automatically when the production hardware crashes, ensuring continuous operation.
- Redundant Software: Backup software or failover software that can automatically take over if the primary software fails, and transfer operations to the standby or backup systems or components. Such software are designed to maintain continuous operations and minimize downtime for critical systems and applications, and recover quickly from any potential failures.
- No Single Point of Failure (SPOF): It implies that no single component or system causes the entire system to fail. In other words, the system is designed with redundancy and fault tolerance to ensure that if one component fails, backup systems or components can take over and maintain continuous operation. Specifically, redundancy in software, hardware, and data eliminates Single Point of Failure (SPOF).
- Scalability: Scalability refers to a system’s capacity to handle increased demand or workload while maintaining performance and availability. This is typically achieved through distributed systems, load balancing, and other techniques that automatically distribute the workload across multiple nodes or components. The main advantage of scalability is its ability to accommodate growth and expansion without significant modifications or upgrades.
In a world where business continuity is non-negotiable, High Availability isn’t just a strategy; it’s the backbone of uninterrupted operations. By understanding its principles and adopting them effectively, you’re better prepared to ensure your systems remain resilient, even in the face of adversity.
Causes of Downtime
Downtime is a nemesis that IT professionals face regularly. It comes in two forms: Planned and Unplanned.
Understanding these different types of downtime and how to effectively manage them is crucial for maintaining system availability and business continuity.
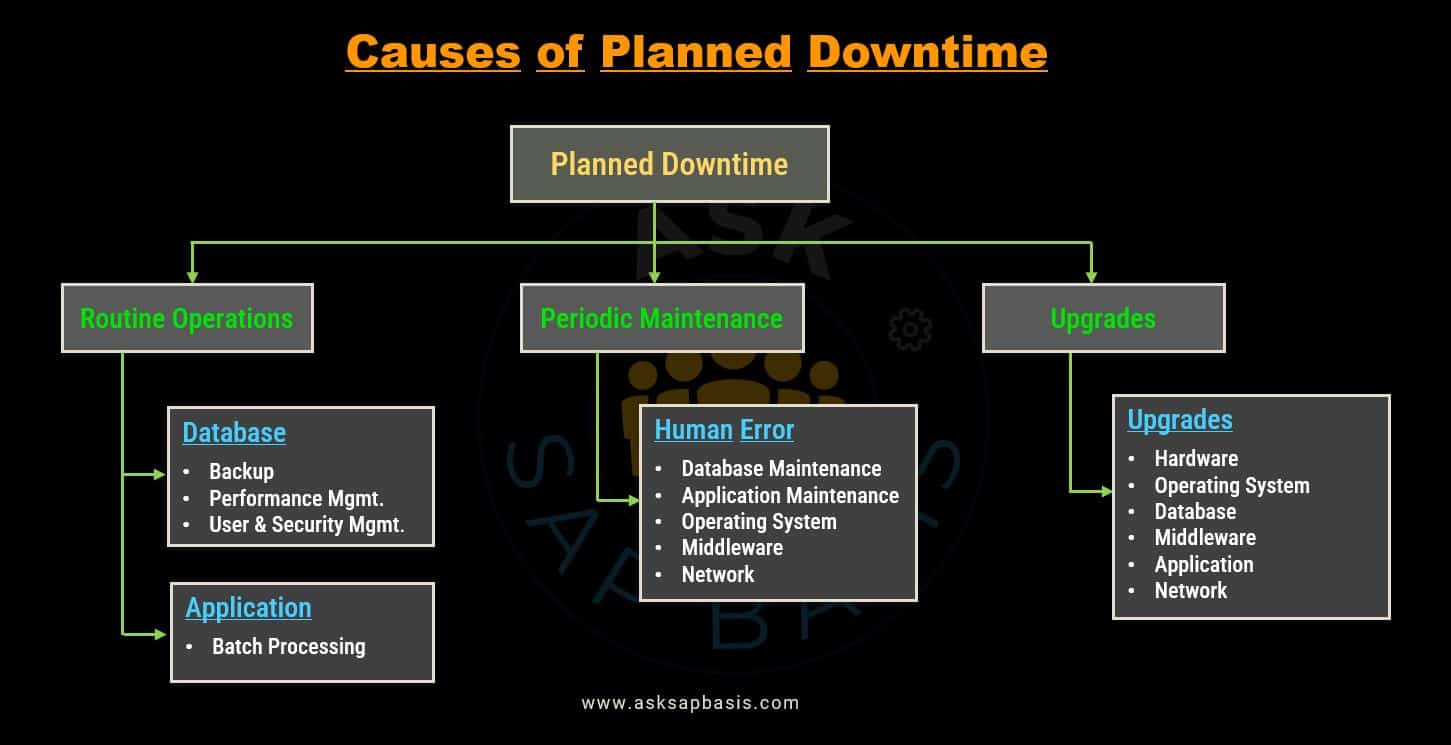
1) Planned Downtime
Planned downtime is a type of downtime that is anticipated and scheduled for maintenance or updates. The IT teams provide advance notification and coordinate a scheduled time window for various tasks, including:
- Software patching
- Hardware upgrades
- Password updates
- Data maintenance
- Disaster recovery rehearsals.
This meticulous planning ensures that work is completed efficiently with minimal disruption to system availability. To further reduce planned downtime, IT teams implement intentional and well managed operational procedures. They also conduct comprehensive threat and risk analysis to identify potential vulnerabilities and threats to the system’s availability and security.
2) Unplanned Downtime
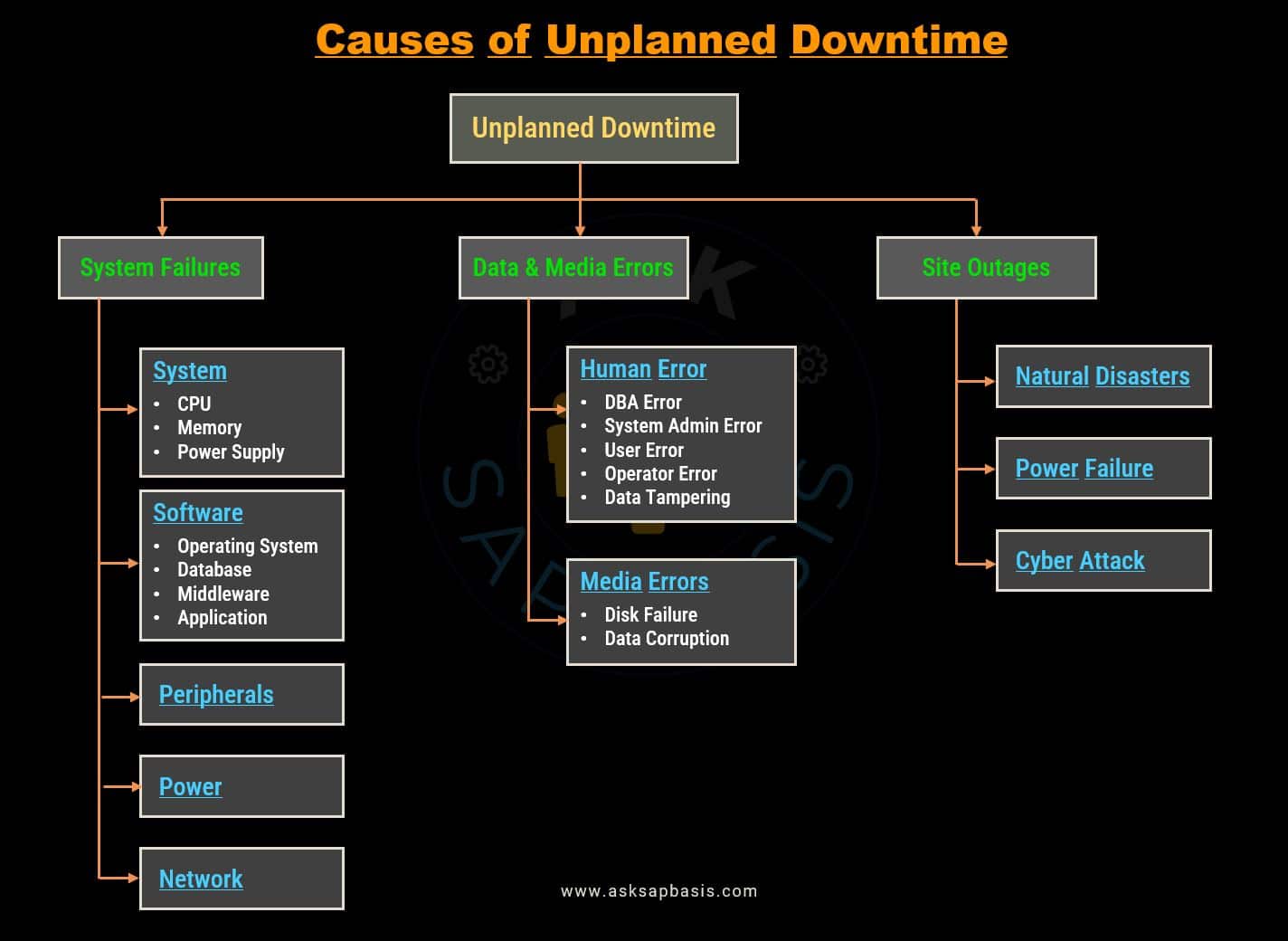
Unplanned downtime, on the other hand, is the unexpected and often disruptive type of downtime. It can occur due to unforeseen failures or issues at the system, infrastructure, or process level. In some instances, these problems may have been foreseeable but were considered unlikely to occur or were deemed to have an acceptable impact.
To address the challenges posed by unplanned downtime, a robust high availability solution should be put in place. Such a solution must possess the capability to:
- Detect failures promptly
- Automatically recover from outages
- Reestablish fault tolerance
These measures ensure that the system remains available and operational, even in the face of unforeseen disruptions.
Effective Downtime Management
Downtime, whether planned or unplanned, should not necessarily be viewed as negative. Instead, it is an opportunity to optimize system performance and security. By taking a proactive approach to downtime management, organizations can enhance their overall IT infrastructure.
Key Strategies for Downtime Management:
- Proactive Planning: Plan maintenance and updates during periods of low user activity to minimize disruption. Develop clear procedures and notifications for planned downtime.
- Threat Assessment: Conduct regular threat and risk assessments to identify potential points of failure and vulnerabilities in your system. Address these issues before they lead to unplanned downtime.
- High Availability Solutions: Invest in high availability solutions that can swiftly detect and mitigate unplanned downtime. These solutions act as safety nets, ensuring uninterrupted service.
- Monitoring and Response: Implement robust monitoring systems that can alert IT teams to potential issues in real-time. Quick response to emerging problems can prevent downtime escalation.
- Disaster Recovery Planning: Develop and test comprehensive disaster recovery plans. Regular rehearsals ensure that your team can efficiently respond to unplanned events.
In conclusion, downtime is an inevitability in IT operations. However, with proper planning, proactive measures, and the right technologies in place, its impact can be minimized. By distinguishing between planned and unplanned downtime and implementing effective strategies, organizations can maintain high availability, enhance security, and ensure uninterrupted business operations.
How HA Works?
High availability (HA) clusters play a pivotal role in ensuring the continuous operation of critical applications and services, striving to keep downtime at an absolute minimum. These clusters comprise groups of servers equipped with redundant software, ready to step in should one machine falter. In this article, we will delve into the inner workings of HA clusters, outlining their key components and mechanisms that make them so effective.
Identifying Failures and Seamless Failover
Imagine a scenario without clustering: if an application or website encounters an issue, it remains unavailable until someone intervenes to resolve the problem. This downtime can lead to lost revenue and frustrated users. High availability architecture eradicates this situation by following a structured sequence:
- Identifying failure when it occurs: High availability clusters continuously monitor the health of their nodes. As soon as a problem is detected, action can be taken.
- Performing application failover: When an issue arises on one node, the HA system seamlessly redirects traffic to another healthy node. This ensures that users experience little to no disruption.
- Restarting or repairing the failed node: Once the failed node is isolated, the HA system can initiate repairs or restarts automatically. This self-healing process reduces the need for human intervention and accelerates recovery.
The Role of Heartbeat in High Availability
High availability servers typically implement a replication technique called as “heartbeat“. This method is designed to monitor the health of cluster nodes through a dedicated network connection. It operates by sending signals or messages between nodes to confirm their active and available status. The heartbeat mechanism plays a crucial role in:
- Detecting potential failures: By constantly exchanging signals, the HA system can swiftly identify if a node becomes unresponsive.
- Triggering failover: In the event of a detected failure, the HA system initiates failover to redirect traffic to another healthy node. This ensures that the application or service remains accessible to users.
Preventing Split Brain Syndrome
Split brain is a crucial condition and should be prevented. This situation occurs when multiple nodes within the cluster lose the ability to communicate with each other, yet they remain active and continue to function independently. This can result from network failure or other issues that disrupt communication between nodes. In such cases, each node may make decisions autonomously, leading to conflicts and inconsistencies. This can result in severe issues, including data corruption, duplication, or loss.
To prevent split brain, techniques such as fencing often referred to as STONITH (Shoot The Other Node In The Head). The primary purpose of fencing is to isolate a malfunctioning node, effectively cutting it off from the rest of the server cluster. By doing so, it prevents the problematic node from interfering with the healthy ones, thus safeguarding the integrity and consistency of data and services.
With these safeguarding techniques (of heartbeat and fencing) in place, high availability clusters play a crucial role in ensuring uninterrupted access to essential services for businesses and users alike.
HA Solutions
We will explore key technologies and best practices, with focus on redundancy and clustering. High Availability (HA) solutions are typically classified into two main categories:
1) Local HA Solutions
Local HA solutions are designed to provide high availability within a provide HA within a single data center deployment. These solutions are essential for minimizing downtime caused by hardware failures, software glitches, or routine maintenance. The cornerstone of local HA is redundancy, and one of the most widely used techniques to achieve it is clustering
2) Disaster Recovery (DR) Solutions
They are geographically distributed deployments designed to safeguard applications from disasters such as floods or regional network outages.
Clustering for High Availability
Clustering is a group of servers that support the High Availability (HA) architecture. Each node in the cluster is constantly monitored through dedicated network connections to ensure optimal operational health. If a node fails, another node seamlessly takes over its operations, ensuring uninterrupted service. This process, known as failover, relies on accurate heartbeat monitoring (instance monitoring) and efficient resource synchronization.
According to the degree of redundancy, HA solutions are designed or architected into different clustering models:
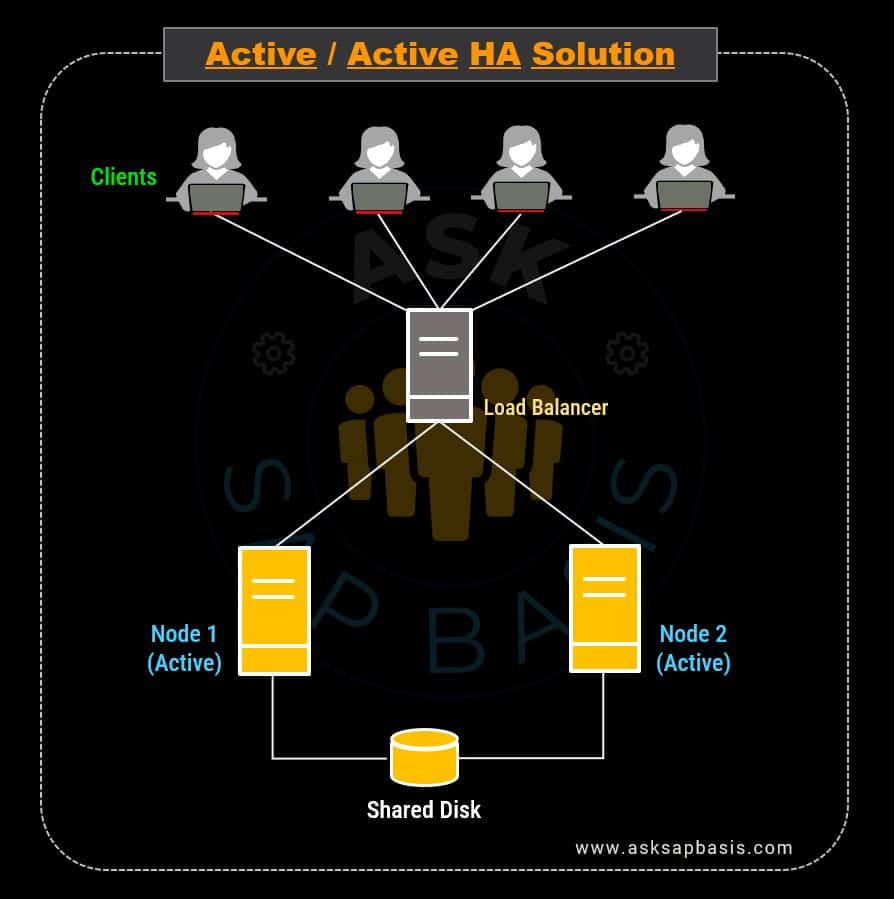
1) Active / Active Solution
In active/active HA solution model, a server cluster consists of two or more identical nodes or instances, all actively handling user requests simultaneously. When a node fails, it automatically connects to another active instance. Once the issue with the failing instance is resolved, the user requests are again distributed to all other instances within the cluster. This kind of active/active solutions are commonly referred as “hot failover clusters“.
The primary advantage of active-active clustering is the ability to efficiently balance workloads across nodes and networks. A load balancer directs client requests to available servers, monitors node and network activity, and employs a predetermined algorithm to route traffic to the nodes best equipped to handle it.
This approach enhances scalability and high availability, system performance, throughput and processing speed, ultimately enhancing fault tolerance and disaster recovery capabilities.
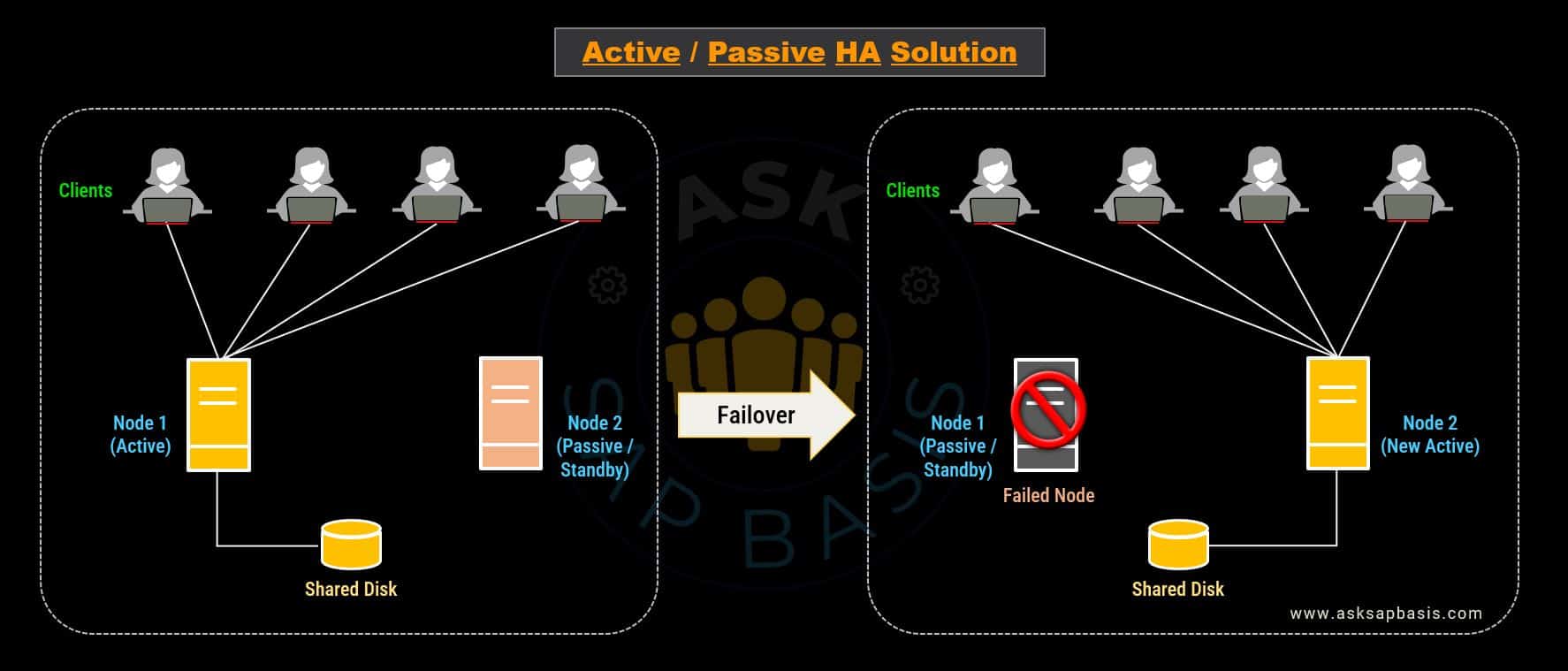
2) Active / Passive Solution
In active/passive HA solution model, only one main or active server node processes all incoming user requests. The backup or passive (or standby node) remains in inactive state, unable to handle any incoming requests. However, when the main or active node fails, the passive node takes over and becomes the new active node. Once the issue with the active node is resolved, all requests are routed back to standby node, which returns to its passive state. This kind of active/passive solutions are commonly referred as “cold failover clusters“
The failover mechanism in active/passive solutions is typically managed by operating system vendor-specific clustering solutions (clusterware). Cluster agents continuously monitors and switch between nodes automatically. If the active node fails, the agent initiates a shutdown and bring up the passive instance, ensuring uninterrupted operation of application services. This same process can be executed manually for planned or unplanned downtime.
HA Metrics
There are several metrics that organizations use to measure the effectiveness of their high-availability (HA) architecture:
1) Availability
This metrics measures the percentage of time that system or application is available and accessible to users. A higher availability percentage indicate better overall performance and reliability.
2) Mean Time Between Failure (MTBF)
This metric measures the average time (often measured in hours) that a system or component operates without experiencing outage. It is derived by dividing the total number of failures observed divided by total number of observed operational hours. A higher MTBF indicates that the system is more reliable system that is less prone to failure.
3) Mean Time To Recover (MTTR)
This metric measures the average duration a system or component takes to recover from a failure or outage. A lower MTTR indicates that the system is more resilient system and able to recover quickly.
4) Recovery Point Objective (RPO)
In simple terms, RPO means how much data can be afford to lose? ie tolerance for potential data loss from an outage. This metric measures the amount of data that can be lost in the event of failure or outage. A lower RPO indicates that the system is better able to recover data and minimize data loss.
5) Recovery Time Objective (RTO)
In simple terms, RTO means how long can you tolerate downtime? ie maximum tolerated duration of application downtime, from an unplanned or scheduled maintenance/upgrade. This metric measures the amount of time it takes to restore a system or application after a failure or outage. A lower RTO indicates that the system is more resilient and able to recover quickly.
MTTR and MTBF quantify system reliability and repair efficiency. RTO and RPO play a broader role in disaster recovery and business continuity planning. Within data-intensive services, RTO and RPO form crucial components of SLAs (Service Level Agreements). They establish expectations between service providers and clients, ensuring fulfillment of commitments to customers, stakeholders, and regulatory bodies
In summary, organizations can develop comprehensive strategies for preventing failures and facilitating efficient recovery by considering RTO and RPO in conjunction with MTBF and MTTR. This approach helps safeguard business continuity, minimize disruptions, and ensure effective incident management.
Disaster Recovery (DR)
Disaster recovery (DR) is an indispensable component of an organization’s strategy to ensure business continuity in the face of natural or man-made disasters, infrastructure failures, or widespread outages. Such disruptive events no only impacts the primary application processing system but also render any standby system ineffective, especially when dealing with large-scale system failures or infrastructure breakdowns.
To effectively counter such scenarios, a well-thought-out and pre-planned approach is essential quickly re-establishing IT functions and their supporting components at an alternate facility when standard repair activities cannot resolve issues within a reasonable timeframe.
DR is a set of process, policies, and procedures specifically designed for restoring critical systems after a catastrophic event.
Here are some of key characteristics that differentiate a DR solution from a high-availability solutions:
- Recovery Mechanism: Unlike high-availability solutions, DR solutions typically do not rely on a hot-standby mechanism. Instead they focus on recovering or restoring applications through manual intervention when necessary. This may involve utilizing backups, replicating data, systems, and infrastructure to resume operations.
- Manual Intervention: DR solutions frequently necessitate manual intervention during the recovery or restoration process. This human involvement ensures a thoughtful and controlled approach to re-establishing critical systems. It includes tasks such as data recovery, system configuration, and infrastructure setup, allowing organizations to tailor the recovery process to their specific needs and circumstances.
- Geographical Seperation: A crucial aspect that sets DR solutions apart is the geographical separation between the primary system and the recovery site. This separation minimizes the risk of a single disaster affecting both the primary and recovery environments. Organizations often choose distant locations to ensure their data and operations remain safe in case of regional disasters.
- Recovery Time Objective (RTO): While high-availability solutions aim for near-instantaneous failover, DR solutions typically have a longer Recovery Time Objective (RTO). RTO is measured in hours or even days, as the focus is on comprehensive recovery and restoration of operations. This extended timeframe allows for thorough testing and validation of the recovered systems.
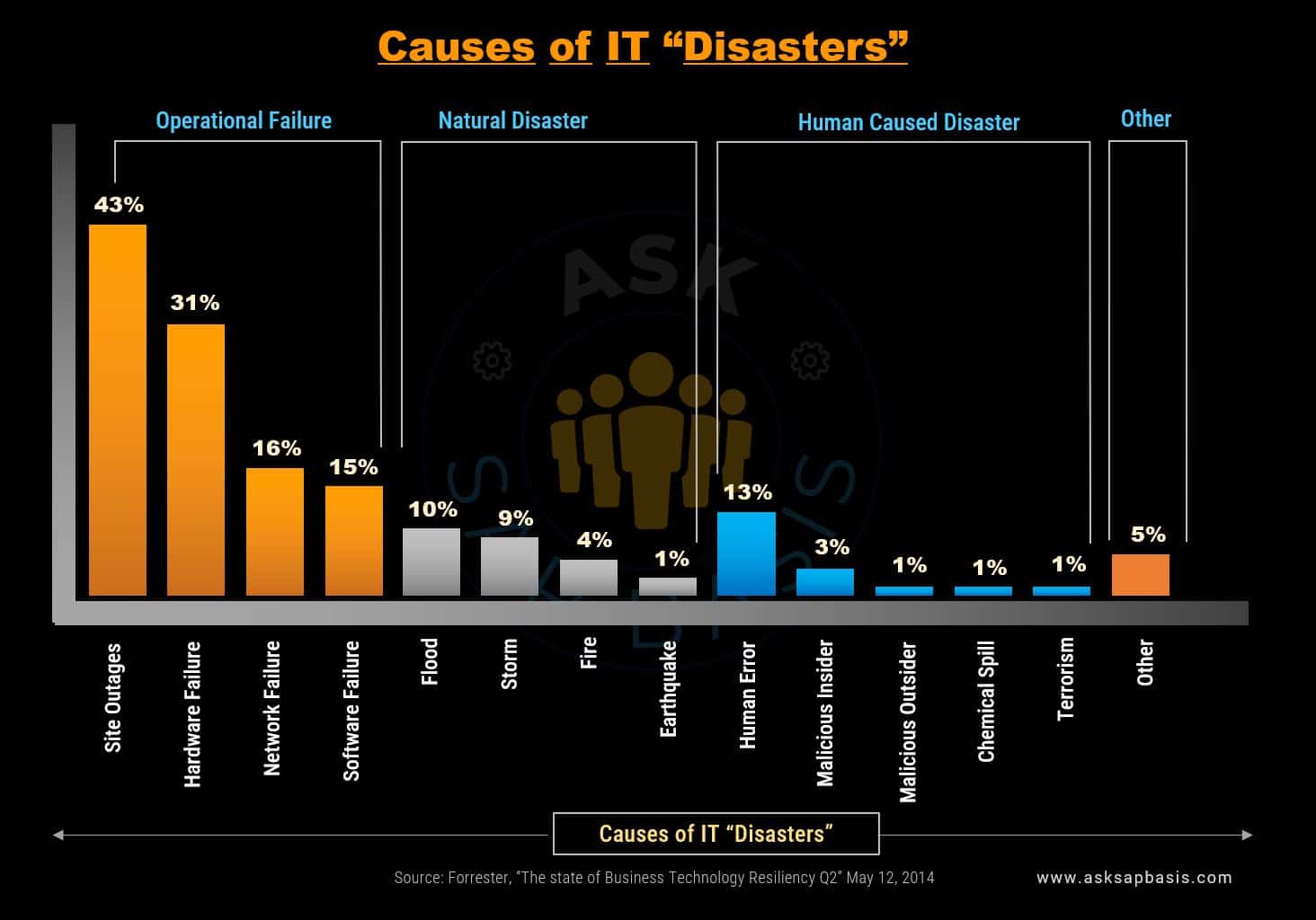
Causes of IT Disaster
Imagine the chaos, when your company’s critical systems suddenly collapse, plunging your operations into turmoil due to a power outage, leaving you scrambling to recover your data and resume operations. Even worse, a malicious insider deliberately sabotages your IT infrastructure, resulting in data loss and major disruptions.
Understanding the root causes of these disaster scenarios is essential for implementing effective risk management strategies and safeguarding your critical systems against potential threats.
Below are some of the common causes of IT disasters:
1) Operational Failures
- Site Outages: Power outage, blackout, electrical failure, energy disruption, power surges etc
- Hardware Failure: Equipment malfunction, hardware breakdown, device failure, computer crash, heat and humidity etc
- Network Failure: Connectivity issues, communication breakdown, network outage, system failure etc
- Software Failure: Application crash, software malfunction, program failure, code error etc
2) Natural Disasters
- Flood: Deluge, inundation, flash flood, water damage etc
- Storms: Cyclone, typhoon, tornado, thunderstorm, sandstorm, monsoon, hailstorm, severe weather etc
- Fire: Blaze, inferno, conflagration, combustion, heat damage etc
- Earthquake: Seismic activity, tremor, ground shaking, tectonic movement etc
3) Human-caused Disasters
- Human Error: Mistake, slip-up, oversight, error, blunder, employee turnover. etc
- Malicious Outsider: Cyber attack, malicious attack, phisher (social engineering, scammer, fraudster etc)
- Malicious Insider: Insider threat, intentional wrongdoing, sabotage, internal attack, data threat etc
- Chemical Spill: Hazardous material release, toxic substance leak, chemical contamination etc
- Terrorism: Cyberterrorism, physical attack, violent incident, extremist activity etc
4) Others
- Others: Unknown cause, miscellaneous issue, theft, vandalism, supply chain disruptions etc
Understanding BCDR
“Mission critical data has no time for downtime. Even for non-critical data, people have very little tolerance“.
In an ever-evolving landscape of modern businesses, organizations often fuse business continuity (BD) and disaster recovery (DR) into a unified initiative known as BCDR (Business Continuity and Disaster Recovery).
BCDR comprises interconnected concepts implemented by organizations to ensure resilience in the face of disruptive events. While business continuity (BC) and Disaster Recovery (DR) complement each other, they have distinct roles in crisis management. The collaborative nature of BCDR empowers business stakeholders to develop more impactful strategies for navigating business disruptions.
- Business Continuity (BC) is a proactive approach and encompasses processes and procedures implemented by organizations to ensure the continuity of mission-critical business operations during and after a disaster. BC takes a broader perspective, focusing on the organization as a whole, including people, processes, and resources, to ensure the continuity of critical functions.
- Disaster Recovery (DR) is a reactive approach and consists of specific steps that the organizations take after the incident. DR narrows its focus to the technological infrastructure, emphasizing the recovery of IT systems, data, and networks to resume operations.
Why is BCDR Important?
There are several reasons why BCDR is important to businesses:
- Minimizing Downtime: Downtime can have severe consequences for businesses, leading to financial losses, damage to reputation, and potential loss of customers. BCDR plays a significant role in minimizing downtime by implementing measures that facilitates quick recovery and resumption of critical operations for organizations.
- Business Resiliency: Disasters and disruptions can happen unexpectedly and in diverse forms, including natural disasters, cyber-attacks, power outages, or human errors. BCDR ensures business resilience by preparing organizations to respond and recover effectively from such incidents, enabling them to maintain the delivery of products or services.
- Data Protection: Data is a valuable asset for businesses, and its loss or compromise can have severe consequences. BCDR includes robust data backup and recovery procedures to safeguard critical information, ensuring its availability even in the face of disasters or system failures.
- Regulatory Compliance: Compliance with legal and regulatory requirements is vital for businesses. Specific regulations exist for data protection, security, and business continuity. Organizations must adhere to these regulations, and implementing BCDR measures helps meet those obligations. This reduces the risk of penalties or legal actions. BCDR practices ensure operations align with legal frameworks and maintain trust with stakeholders and regulatory authorities.
- Maintaining Customer Trust: Customers rely on businesses to deliver products, services, and support consistently. Prolonged interruptions in operations can erode customer trust and loyalty. Implementing effective BCDR strategies allows businesses to demonstrate their preparedness in handling unexpected events and ensuring reliable service, thereby reassuring customers.
- Safeguarding Employees and Assets: BCDR not only focuses on technology and data but also considers the safety and well-being of employees and physical assets. Disaster recovery plans may include evacuation procedures, emergency response protocols, and measures to protect physical infrastructure, ensuring the safety of employees and minimizing potential damage.
- Competitive Advantage: Organizations that prioritize BCDR demonstrate their commitment to reliability, resilience, and preparedness. This can provide a competitive advantage, as customers and partners are more likely to trust and prefer organizations that have robust continuity and recovery measures in place.
In conclusion, BCDR is vital for businesses to mitigate the impact of disruptions, ensure continuity of operations, protect critical data, meet legal requirements, maintain customer trust, safeguard employees and assets, and gain a competitive edge. By investing in BCDR, organizations can minimize downtime, recover quickly, and continue operating effectively even in the face of unforeseen events or disasters.
BCDR Planning
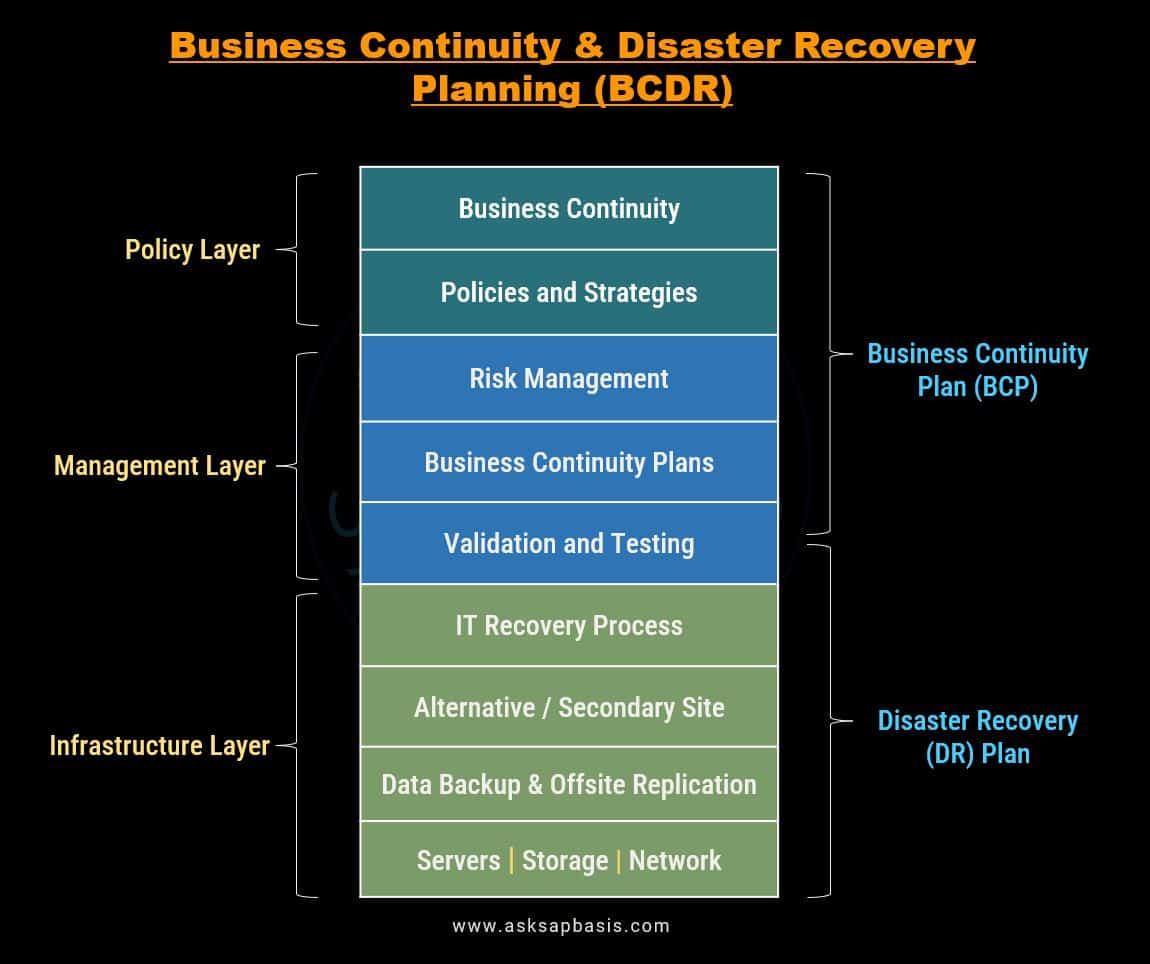
Business Continuity Plan (BCP)
A Business Continuity Plan (BCP) is a comprehensive document that acts as a guiding light during turbulent times, outlining strategies, procedures, and actions necessary to ensure business operations continue seamlessly during and after disruptive incidents. It covers various facets of the organization, addressing both operational and strategic considerations.
Here is a detailed breakdown of what a typical Business Continuity Plan (BCP) includes:
1) Introduction and Scope
This section provides an overview of the BCP, define its purpose and objectives, and outlines the scope and boundaries of the plan.
2) Executive Summary
Executive summary offers a high-level summary of the BCP, highlighting key strategies, critical functions and recovery priorities. It provides a concise overview for management and stakeholders.
An executive summary is a concise view of the BCDR plan or strategy, highlighting its key components and objectives. It provides senior management or key stakeholders with a concise summary of the plan’s purpose, approach, and key considerations.
It typically includes following information:
- Purpose: Clearly state the reason for developing the BCDR plan.
- Scope: Describe which systems, processes and resources are included in the plan.
- Objectives: Outlines the primary goals and objectives of the BCDR plan.
- Risk Assessments: Summarize key findings from the risk assessment process highlighting potential threats and vulnerabilities.
- Strategies and Mitigation: Provides an overview of the strategies and measures to mitigate risks and ensure continuity, such as backup procedures, alternate site arrangements and emergency response protocols.
- Roles and Responsibilities: Outline the key roles and responsibilities of the individuals and teams involved in the BCDR plan, including:
- BCDR team: Manage and coordinate BCDR efforts.
- Incident Response team: Respond to incidents and disruptions.
- Communication Liaisons: Communicate with stakeholders, employees and external parties during disasters or disruptions.
- IT Departments: Handles backup, recovery and maintenance.
- Executive Management: Overseeing and making critical BCDR decisions.
3) Organization Background
This section provides detailed information about the organization, including its structure, key stakeholders, critical business functions, dependencies, and interdependencies. It also identifies the potential risks and threats that could impact business operations.
4) Distribution List and Storage Location
Distribution list outlines the individuals or roles within the organization that should have access to the BCP. This includes key stakeholders, decision-makers, department heads, and designated team members responsible for executing the plan during a disruptive incident. The distribution list ensures that the right people have access to the plan when it is needed most.
Storage location refers to physical or digital location where copies of BCP are kept. This could be a secure server, a cloud-based storage system, a designated folder on shared drive etc. The storage location should be easily accessible to authorized personnel.
By explicitly documenting the distribution list and storage location within the BCP the organization ensures that the plan can be readily accessed and deployed in times of crisis. This information serves as a reference for individuals to consult or update the plan, guaranteeing its availability and effectiveness in guiding the organizations response and recovery efforts.
5) Risk Assessment and Business Impact Analysis (BIA)
The risk assessment process involves identifying and evaluating potential risks that could affect the organization’s operations. It includes a systematic analysis of internal and external factors that pose threats to the business, such as natural disasters, technological failures, security breaches, or supply chain disruptions. By identifying these risks, organizations can prioritize their mitigation efforts and allocate resources effectively to minimize the likelihood and impact of potential disruptions.
To summarize, it typically includes following information:
- Identify Risks: Identify potential risks that could disrupt business functions.
- Assess Probability: Evaluate the likelihood of each identified risk that occurs.
- Evaluate Impact: Assess the potential consequences of each risk.
- Prioritize Risks: Determine the priority of risks based on probability and impact.
- Mitigation Strategies: Develop strategies to minimize the probability and impact of risks.
- Documentation: Document findings, risks, probabilities, impacts and mitigation strategies.
- Review and Update: Regularly review and update the risk assessment process.
Business Impact Analysis (BIA) is an essential step in developing a BCP as it assesses the potential impacts of disruptions on critical business functions. It involves analyzing the dependencies, interdependences and recovery time objectives (RTO) for various businesses. By conducting a BIA, organizations can determine the financial, operational, reputational and regulatory impacts that would arise from disruptions. This information allows them to prioritize their recovery efforts, allocate resources, and develop appropriate strategies to minimize downtime and maintain essential operations.
To summarize, it typically includes following information:
- Identify critical functions and processes.
- Define impact criteria for each function.
- Assess potential consequences of disruptions.
- Establish recovery objectives (RTO and RPO).
- Analyze dependencies between functions.
- Data gathering and analysis.
- Analyze findings to understand the impacts and recovery requirements.
- Utilize BIA results to inform BCDR strategies.
- Regularly review and update the BIA with new risk that may emerge, or critical functions change.
Together, risk assessment and BIA provide a comprehensive understanding of potential risks and their potential impacts. This information serves as a foundation for developing strategies and contingency plans within the BCP.
6) Incident Response and Emergency Procedures
This section describes the protocols and procedures to be followed during various types of incidents. It typically includes following information:
- Defined procedures for responding to incidents.
- Clear roles and responsibilities during emergencies.
- Overview of incident response team, plus special point of contacts (SPOCs) in times of crisis.
- Communication protocols for timely information sharing.
- Activation of emergency response teams.
- Effective coordination with external stakeholders.
- Implementation of incident management systems.
- Conducting regular training and drills to ensure readiness.
- Periodic evaluation and improvement of response capabilities.
7) Emergency Communication and Notification Strategies
Communication and notification within BCP are essential for ensuring effective information flows during crises. They outline communication channels, methods, and protocols to promptly inform employees, customers, partners, and stakeholders about the situation, recovery progress, and any updates.
Such plans emphasize timely and transparent communication, utilizing various channels such as emails, phone calls, and dedicated platforms. Clear guidelines and designated communication personnel or teams ensure efficient coordination. Regular reviews and refinements enhance the plans’ effectiveness, enabling organizations to maintain stakeholder confidence and facilitate a coordinated response.
It typically involves following information:
- Key stakeholders to be informed during a disruption.
- Plans emphasizing timely and transparent communication using various channels such as emails, phone calls and dedicated platforms.
- Up-to-date contact information for stakeholders.
- Emergency notification system for swift communication.
- Clear guidelines and designated communication personnel or team to ensure efficient coordination.
- Communication or message templates for different scenarios.
- Detailed escalation guidelines and procedures.
- Strategy to provide regular updates to stakeholders during disruption.
- Test and train employees on communication procedures.
- Plan for post-incident communication and resolution updates.
- Regular review mechanisms and refinements to enhance the plans effectiveness.
8) Business Recovery Procedures
This section outlines the systematic steps required to restore critical business functions following a disruptive incident. It typically includes following information:
- Provide step-by-step response and recovery procedures for each disaster scenario.
- Restore critical business functions.
- Relocate operations (if necessary).
- Restoring IT systems and infrastructure.
- Prioritizing recovery efforts.
- Coordinate with external vendors and suppliers.
- Ensure seamless resumption of operations.
- Continuous monitoring and evaluation of recovery progress.
9) Training and Awareness Programs
Training and awareness programs play a crucial role in ensuring the effectiveness of a Business Continuity Plan (BCP). These programs are designed to educate and equip employees with the knowledge and skills necessary to respond effectively during a crisis.
It typically includes following information on:
- Educational programs for employees.
- Enhancing knowledge and skills.
- Building awareness of BCP procedures.
- Conducting regular training sessions.
- Simulating crisis scenarios.
- Promoting a culture of preparedness.
- Testing response capabilities.
- Continuous improvement through feedback and evaluation
10) Plan Activation and Escalation Procedures
This section involve the crucial steps of initiating the Business Continuity Plan (BCP) and escalating incidents during a crisis.
It typically includes following information on how-to:
- Initiate and trigger the plan during crisis.
- Well-defined activation criteria.
- Establish escalation protocols for escalating issues to appropriate levels based on severity and impact.
- Engage key stakeholders and decision-makers.
- Coordinate response efforts.
- Ensure effective communication and collaboration.
- Continuously monitor and adjust response activities.
By following these activation and escalation procedures, organizations can respond promptly and effectively to disruptions, minimizing their impact and ensuring the continuity of critical operations.
11) Legal and Regulatory Compliance
Adhering to legal, contractual, and regulatory obligations is paramount within the context of BCP. Organizations meeting these obligations ensure compliance with necessary legal and regulatory requirements governing their operations. By incorporating these obligations into the BCP, organizations demonstrate commitment to compliance, risk management, and responsible business practices.
Failure to meet these obligations can result in legal and financial consequences, reputational damage, and disruptions to business operations.
12) Metrics and Key Performance Indicators (KPI)
Metrics and KPIs play a crucial role in measuring the impact and recovery stages of BCP. These metrics provide quantifiable benchmarks to assess the severity and duration of disruptions, enabling organizations to test the effectiveness of their recovery efforts.
One important metric is “maximum tolerable downtime (MTD),” which establishes the acceptable time limit for restoring critical functions. By monitoring and tracking these metrics and KPIs, organizations gain insights into the efficiency and effectiveness of their recovery processes. This information enables them to make informed decisions and continuously improve their BCP, enhancing resilience and minimizing downtime.
13) Integration of Service Level Agreements (SLAs)
SLAs define performance objectives and expectations between the organization and its service providers or vendors. They establish agreed-upon standards for service delivery, including response time, availability, and recovery time objectives (RTO).
By incorporating SLA’s into BCP, organizations can ensure that these contractual agreement are considered when measuring the impact of disruptions and assessing the progress of recovery efforts. SLA’s provide framework for evaluating performance against pre-determined targets and hold service providers accountable to meeting their commitments in restoring critical services within the defined timeframes.
In conclusion, its important to note that the specific activities and strategies outlined in the above BCP plan may vary depending upon the unique characteristics and requirements of each organization.
Disaster Recovery Plan (DRP)
A Disaster Recovery Plan (DRP) is a crucial component of crisis management, working hand in hand with business continuity.
A business continuity plans enable organization to continue providing services during and after an incident, ensuring uninterrupted operations. Whereas a disaster recovery plan is a comprehensive framework that outlines the steps and procedures to mitigate risks, ensure business continuity and expedite recovery in the face of unforeseen disasters.
Creating a disaster plan involves several key steps:
1) Analysis of IT Systems
Perform a thorough analysis of the organization’s IT system, encompassing networks, servers, databases, and critical data. Identify dependencies, vulnerabilities, and potential points of failure. This analysis assists in determining the required recovery steps and prioritizing critical resources.
2) Inventory of Relevant Hardware and Software
Develop a comprehensive inventory of vital hardware components (servers, routers, switches, etc.) and software applications that drive the organization’s operations. Incorporate dependencies and interdependencies among these components. This inventory aids in accurately documenting, maintaining, and executing recovery procedures. Furthermore, it will facilitate the replacement of necessary hardware and software during the recovery process.
3) Identify Potential Risks
Begin by identifying the types of disasters or events that could disrupt your business operations, such as natural disasters, power outages, cyberattacks, or equipment failures etc. Assess the potential impact of these risks on your organization.
4) Assess Critical Processes and Assets:
Identify the key processes, systems, applications, and data that are critical for your business operations. Determine their importance and prioritize them based on their impact on your organization.
5) Define Recovery Objectives
Set specific recovery objectives, such as recovery time objectives (RTO) and recovery point objectives (RPO). RTO defines the maximum allowable downtime, while RPO specifies the maximum acceptable data loss in case of a disaster.
6) Develop a Response Team
Create a dedicated team responsible for implementing and managing the disaster recovery plan. Assign roles and responsibilities to team members and ensure they have the necessary expertise and training.
7) Create Backup and Recovery Procedures
Establish procedures for regular data backups and define the mechanisms for restoring data and systems. Consider both on-site and off-site backups to protect against localized disasters. Your plan should address few key questions like:
- Who will perform the disaster recovery tasks?
- What are the required timelines for completing recovery tasks to meet RTO & RPO requirements?
- In what ways can disaster recovery procedures differ across various facilities or sites?
8) Establish Communication Protocols
Set up communication channels and protocols to facilitate effective communication among team members, employees, customers, and stakeholders during a disaster. This involves establishing an emergency communication system, to ensure timely and reliable communication exchange.
10) Test The Plan
Regularly test your disaster recovery plan to validate its effectiveness. Conduct drills and simulations to identify any gaps or areas for improvement. Adjust the plan based on the feedback and lessons learned from these tests.
11) Document and Maintain The Plan
Document the entire disaster recovery plan, including procedures, contact information, and any necessary recovery documentation. Keep the plan up to date as your organization evolves, and periodically review it to ensure its relevance and accuracy.
12) Train Employees
Provide training to employees on their roles and responsibilities during a disaster. Familiarize them with the plan and conduct mock drills and awareness programs to ensure everyone understands their part in the recovery process.
13) Review and Improve
Regularly review and revise your disaster recovery plan to reflect the evolving needs of your organization, technology, and potential risks. Continuously improve the plan based on feedback, lessons learned, and industry best practices.
By diligently following these steps, you can develop a comprehensive and effective disaster recovery plan that minimizes the impact of disasters, ensuring business continuity even in the face of unforeseen events. Your organization will be well-prepared to navigate crises and emerge stronger than ever.
Useful Resources
- SAP Note 1552925: Linux – High Availability Cluster Solutions
- SAP Note 527843: Oracle RAC support in the SAP environment


